版本信息:
在本文的分析过程中,我们使用下面这个示例程序:
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> int main (void ) {int a = 0 ;int *b = NULL ;scanf ("%d" , &a);if (a == 0 ) {1 ;return ;
后续提到该程序时,统一用“示例程序”代替。
Fuzzing简介
Fuzzing是一种通过生成大量testcase对程序进行测试,从而找出程序中潜在问题的技术。
显然,我们在测试中让越多的代码执行起来,越有可能找到漏洞,这与testcase的生成方式直接相关。因此我们可以总结出:一个良好的Fuzzing工具应该有能力生成路径覆盖率尽可能大的testcase。
根据已知条件的不同,Fuzzing大致可以分为三类:
White box
fuzzing:已知源程序的全部语义信息,并据此生成可以遍历所有执行路径的testcase
Black box
fuzzing:程序的任何信息都未知,利用某种指定的规则来生成testcase
Grey box fuzzing:介于Black,White box之间,这种方式的典型代表是code
instrumentation,其主要方法是依据已有的testcase的运行结果主动改变新testcase的变异(即生成新的testcase的方式)方向。从而使testcase的代码覆盖率逐步扩大。注意这要求我们提供一些已知的testcase作为seed。我们今天提到的AFL便采用的是这种方式。
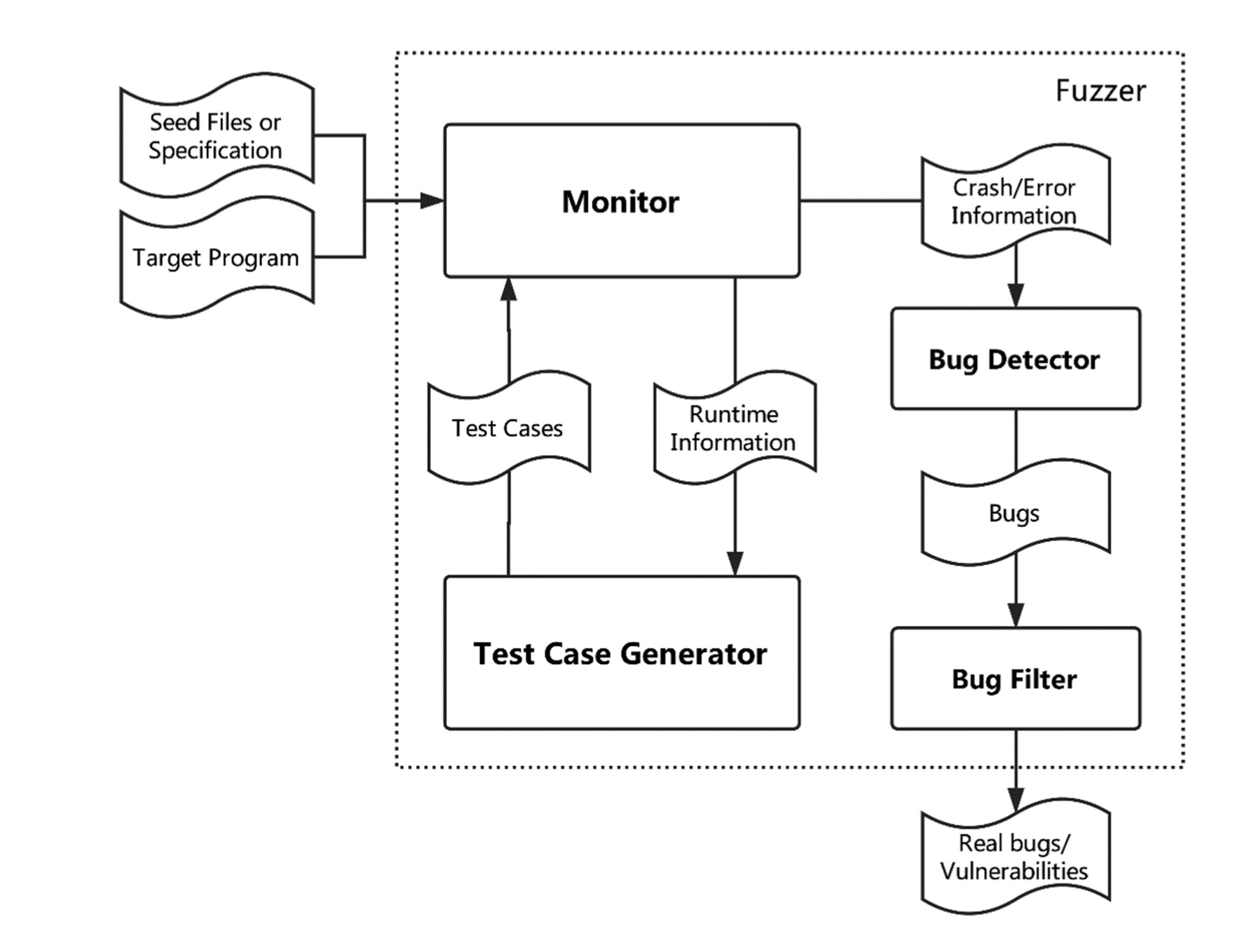
一般来说,一个fuzzing工具的主要工作流程如下2
引言
AFL是一个Grey
box测试工具。根据前面提到的Fuzzing介绍,我们可以初步了解AFL的工作原理:
使用用户提供的testcase对程序进行测试,并计算覆盖率
根据覆盖率信息生成合适的新testcase,再次测试
重复上述操作,当程序crash时,记录使用的testcase
这个简略的工作原理为我们带了了更多的问题,如下面两个:
如何从一个正在运行的二进制程序中获取覆盖率信息
如何生成可能覆盖更多路径的testcase
官方白皮书1
覆盖率信息的获取
这里我们仅仅研究afl利用QEMU进行的二进制层面的测试方式。
在QEMU中,二进制程序被拆分成一种基本等价于基本块的结构TranslationBlock。基于基本块的定义,我们知道一个TranslationBlock是二进制程序的一个最大连续执行序列,因此在一个TranslationBlock中必然不可能存在分支,同时每个TranslationBlock都有可能是分支语句的目标。
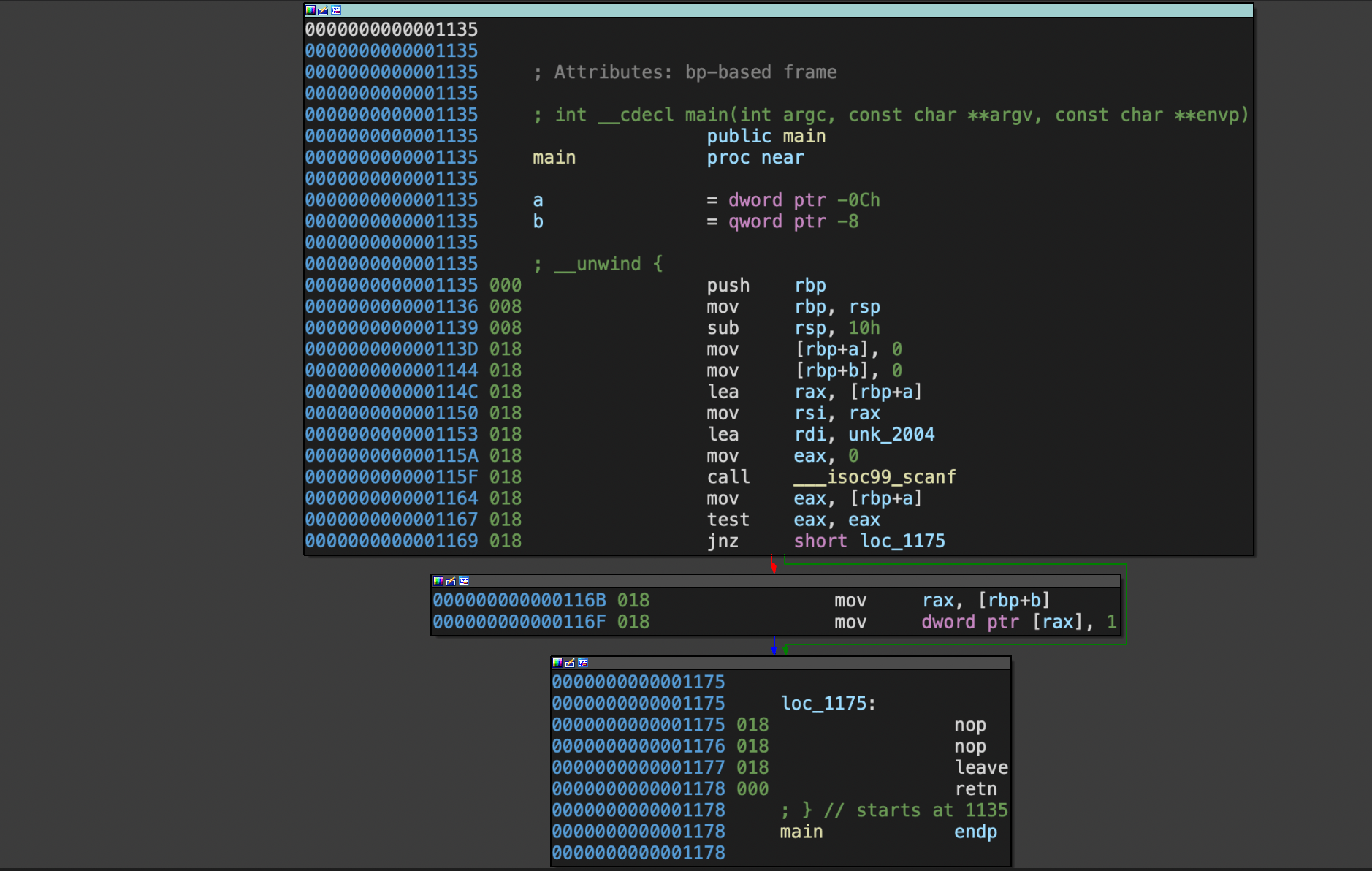
例如示例程序可以被拆分成下面几个基本块:
在这个程序中,我们可以看到0x0001135,0x000116B,0x0001175这几个地址都位于块的起始。那么不难想到,只要知道程序是否执行到这几个地方,就可以推出测试的覆盖率。那么问题转化为如何知道二进制程序是否执行到这几个地方,更进一步的,知道这几个地方执行到了几次?
首先,对于一个二进制程序,qemu在进行一系列初始化工作后,将会到达一个名为cpu_exec的函数(qemu_mode/qemu-2.10.0/accel/tcg/cpu-exec.c:680)3
1 main -> cpu_loop -> cpu_exec
该函数是模拟执行二进制程序的main loop,有关键代码如下
1 2 3 4 5 6 7 8 9 10 while (!cpu_handle_exception(cpu, &ret)) {NULL ;int tb_exit = 0 ;while (!cpu_handle_interrupt(cpu, &last_tb)) {
可以看到,程序利用tb_find函数找到(实际上牵扯到一个懒惰加载过程,不再赘述)下一个将被执行的TranslationBlock,然后利用cpu_loop_exec_tb函数来执行该块。为了获得程序的执行路径,我们可以在执行过程中进行某种插桩操作,AFL正是这么做的,在真正用于执行TranslationBlock的函数cpu_tb_exec中,我们可以看到这样的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static inline tcg_target_ulong cpu_tb_exec (CPUState *cpu, TranslationBlock *itb) if (itb->pc == afl_entry_point) {
我们展开的宏AFL_QEMU_CPU_SNIPPET2便是获取执行信息的关键。
进程间信息传递
首先明确一点:qemu是AFL主程序开启的一个子进程,因此我们首先需要解决进程间的信息传递问题,这里AFL使用了一种非常巧妙的方式。为了对其进行诠释,我们首先研究第一个TranslationBlock被执行时,afl_setup();如何完成初始化工作。(注意这里我们暂且不谈afl_forkserver(cpu);的作用。
我们首先研究afl_setup(void)函数的实现
该函数的主要作用是设置共享内存,从而开辟一条AFL进程与qemu进程通信的通道。注意这里出现了一个小问题:在开辟该通道之前,AFL如何与qemu通信?这里AFL使用了环境变量来解决该问题:AFL进程首先想操作系统申请一块共享内存,获取其id,然后将一个名为SHM_ENV_VAR的环境变量设置为该id,之后 启动的qemu进程的栈中就会保存有该变量,使用getenv函数获取即可,实际上还有更多初始化信息通过环境变量传达,参见官方文档4
下面是AFL part:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 EXP_ST void setup_shm (void ) {if (!in_bitmap) memset (virgin_bits, 255 , MAP_SIZE);memset (virgin_tmout, 255 , MAP_SIZE);memset (virgin_crash, 255 , MAP_SIZE);0600 );if (shm_id < 0 ) PFATAL("shmget() failed" );"%d" , shm_id);if (!dumb_mode) setenv(SHM_ENV_VAR, shm_str, 1 );NULL , 0 );if (trace_bits == (void *)-1 ) PFATAL("shmat() failed" );
下面是qemu part
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 static void afl_setup (void ) {char *id_str = getenv(SHM_ENV_VAR),"AFL_INST_RATIO" );int shm_id;if (inst_r) {unsigned int r;if (r > 100 ) r = 100 ;if (!r) r = 1 ;100 ;if (id_str) {NULL , 0 );if (afl_area_ptr == (void *)-1 ) exit (1 );if (inst_r) afl_area_ptr[0 ] = 1 ;if (getenv("AFL_INST_LIBS" )) {0 ;-1 ;
通过上面的分析,我们初步了解了AFL进程与qemu进程关于覆盖率信息通信的方式,现在我们来分析依赖于此的核心算法。
核心算法
重点关注用于插桩的函数afl_maybe_log(itb->pc);,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 static inline void afl_maybe_log (abi_ulong cur_loc) {static __thread abi_ulong prev_loc;if (cur_loc > afl_end_code || cur_loc < afl_start_code || !afl_area_ptr)return ;4 ) ^ (cur_loc << 8 );1 ;if (cur_loc >= afl_inst_rms) return ;1 ;
首先分析插桩过程的部分(1):
目的:将block地址映射到共享内存索引空间中,并尽可能保证均匀且唯一
已知:MAP_SIZE是共享内存的大小,它是AFL源码中确定的,默认值为 1
<< 16
下面看AFL的做法:
假设有地址0x400081fa60:
1 2 3 4 5 0x000400081fa6
可以看到,经过这两部步转化,结果保留了原地址低28位的信息,对不同的地址具有很好的区分度。
然后分析插桩部分(2):
如果仅仅以cur_loc为索引,我们只能知道程序执行到了哪个位置。要获取更进一步的信息,如一个基本块被执行时,上一个被执行的块是哪一个。这就需要我们将当前被执行的块与之前被执行的块联系起来。在AFL中,实现这一过程的关键变量是prev_loc。
每当一个桩被执行到时,以cur_loc ^ prev_loc值为索引的共享内存中的相应位置值加一,代表此处被hit一次(注意这里并没有考虑到溢出的情况,因为开发者认为这是一种“acceptable
performance
tradeoff”)。这个做法在传递了hit信息的同时通过链状的(cur_loc, prev_loc)元组给出了控制流信息。
然而还有两个问题亟待解决:
在一个仅包含一个基本块的循环中,cur_loc ^ prev_loc = 0恒成立,这显然不是我们想要的。
当两个基本块的执行顺序改变时,如A -> B变为B -> A,由于异或是可交换的,我们无法确定具体的顺序。
操作prev_loc = cur_loc >> 1;解决了这个问题,它通过每次移位保证了二元组构成的链的有序性,同时解决了循环的问题。
小结
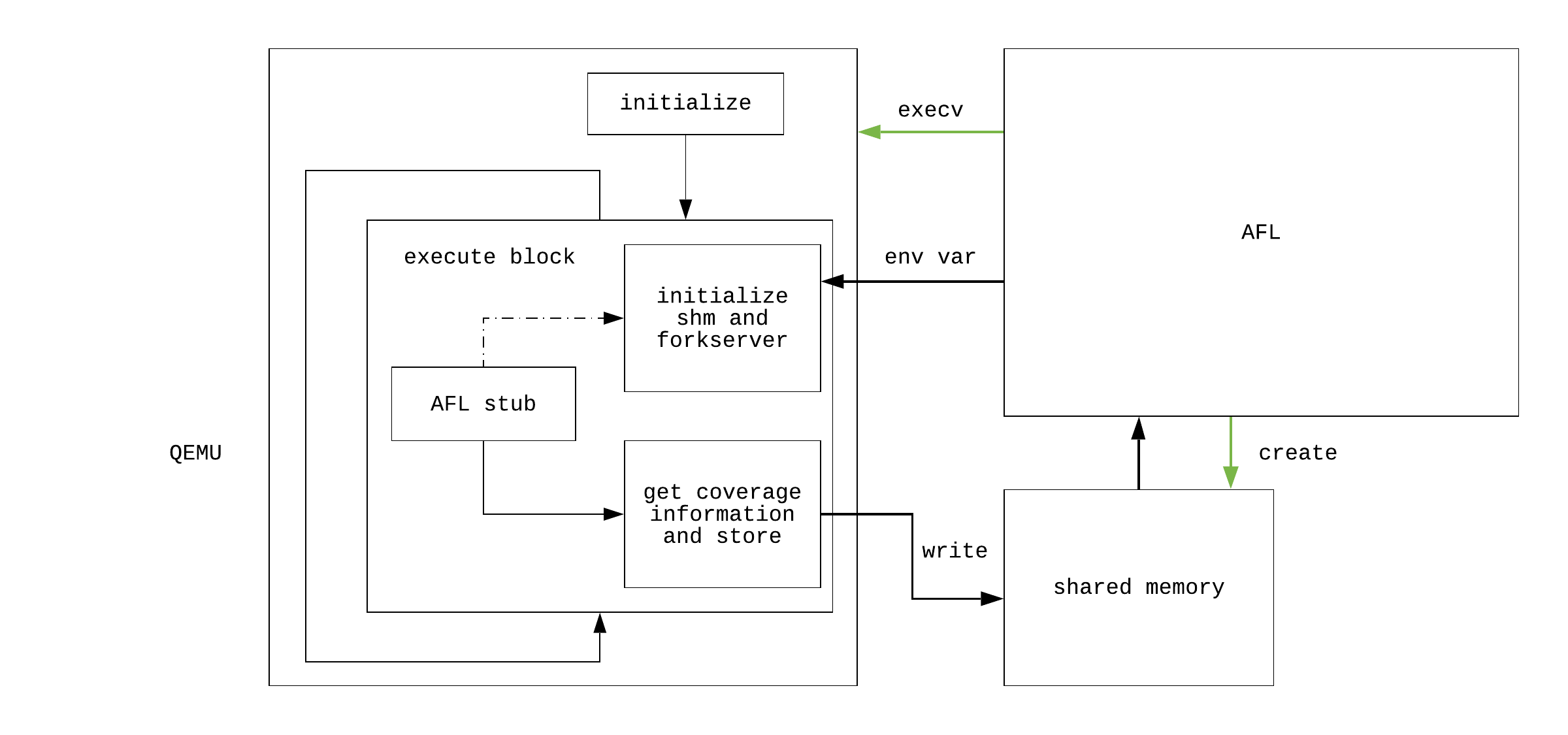
至此,我们已经分析完毕qemu如何传递覆盖率信息给AFL进程,如图所示:
接下盘点我们在这个分析过程中产生的问题,以及之前提出,但尚未解决的问题:
AFL如何从共享数组的索引中恢复出控制流信息
覆盖率信息如何改变testcase的变异方式
AFL如何利用多进程加速分析
forkserver概述
管道初始化
我们首先分析AFL侧的forkserver,首先创建两个管道,之后我们会看到它们的作用:
1 2 int st_pipe[2 ], ctl_pipe[2 ];if (pipe(st_pipe) || pipe(ctl_pipe)) PFATAL("pipe() failed" );
然后调用fork函数创建新进程,在子进程中,我们首先对本进程所能够使用的资源进行限制,然后调用execv函数来创建子进程
AFL子进程:initializing
首先设置子进程的资源限制并将其设置为守护进程(这是因为这个进程才是真正的server,后面分析到qemu侧时我们将会发现这种设计的优秀之处)
1 2 3 4 5 6 7 8 9 10 11 12 13 struct rlimit r ;if (mem_limit) {rlim_t )mem_limit) << 20 ;0 ;
接下来我们设置子进程的文件描述符,我们只关注crash,而这是通过信号机制来传输的,因此关掉输出流和错误流。
注意上面提到过这个子进程才是真正的server,该server通过一个管道来和AFL进程通信,这一部分代码设置了它。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 1 );2 );if (out_file) {0 );else {0 );if (dup2(ctl_pipe[0 ], FORKSRV_FD) < 0 ) PFATAL("dup2() failed" );if (dup2(st_pipe[1 ], FORKSRV_FD + 1 ) < 0 ) PFATAL("dup2() failed" );0 ]);
最后,我们执行target_path,在qemu模式下,这个语句相当于起了一个qemu进程,真正的servre就运行在这个进程中。
1 2 3 4 5 6 execv(target_path, argv);exit (0 );
在经过了上述初始化工作之后,AFL主进程和forkserver之间建立起了一个全双工的通信管道:forkserver可以从
FORKSRV_FD读取来自AFL的控制指令,往FORKSRV_FD + 1中写反馈给AFL的信息。
QEMU侧:the real server
在前面的分析中我们可以看到,在执行第一个基本块之前,qemu将会完成共享内存的初始化以及forkserver的初始化,这里我们用于后者的afl_forkserver函数:
首先,我们需要保证共享内存已经初始化,同时通过检查FORKSRV_FD + 1是否可写来确定本进程是否是一个AFL进程运行起来的。
1 2 3 4 5 6 if (!afl_area_ptr) return ;if (write(FORKSRV_FD + 1 , tmp, 4 ) != 4 ) return ;
接下来我们就进入了forkserver的main loop:
首先创建一个管道,用于向fork出来的子进程通信,这个管道的具体用途我们后面会提到 .
接下来我们尝试从FORKSRV_FD读取4个字节,若读取成功,说明AFL进程告知server需要起一个新的子进程,我们在配置好管道后执行fork操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 while (1 ) {pid_t child_pid;int status, t_fd[2 ];if (read(FORKSRV_FD, tmp, 4 ) != 4 ) exit (2 );if (pipe(t_fd) || dup2(t_fd[1 ], TSL_FD) < 0 ) exit (3 );1 ]);if (child_pid < 0 ) exit (4 );
在fork出来的子进程中,我们关闭不需要的文件描述符,然后直接return到qemu的main
loop,执行目标程序:
1 2 3 4 5 6 7 if (!child_pid) {1 ;1 );0 ]);return ;
在server进程中,我们通过管道告知AFL进程新创建的子进程的pid(其作用后面 我们会提到),然后调用afl_wait_tsl函数进入一个等待循环(后面会分析其作用)
1 2 3 4 5 6 7 close(TSL_FD);if (write(FORKSRV_FD + 1 , &child_pid, 4 ) != 4 ) exit (5 );0 ]);
最终我们获取到子进程的退出状态并反馈给AFL进程。
1 2 3 4 if (waitpid(child_pid, &status, 0 ) < 0 ) exit (6 );if (write(FORKSRV_FD + 1 , &status, 4 ) != 4 ) exit (7 );
qemu在执行跨架构文件时,会将其余架构的指令以基本块为粒度翻译到本架构,这一过程是相对耗时的,因此qemu采取的策略是执行到一个基本块时才对其进行翻译,翻译后的基本块会被保存下来以提高下次执行到该块时的速度。这一过程在前面提到过的tb_find函数
因此为了不浪费在子进程中翻译过的块,我们开辟了一条从子进程到server的管道。在server中我们使用afl_wait_tsl监听该管道,每当一个新的块被翻译,就会触发一个名为afl_request_tsl来告知server,然后server便会通过一系列操作获取一份子进程中被翻译的块的拷贝。在下一次fork中,新的子进程就不必再翻译同一个块。这是一种巧妙的优化措施。
AFL父进程:error handling
接下来我们分析AFL进程的后续操作:
首先关闭无用的文件描述符,并设置与管道有关的变量
1 2 3 4 5 close(ctl_pipe[0 ]);1 ]);1 ];0 ];
接下来设置一个定时器,等待server通过管道向本进程发送信息,以此来确定server是否开始运行:
1 2 3 4 5 6 7 8 9 10 it.it_value.tv_sec = ((exec_tmout * FORK_WAIT_MULT) / 1000 );1000 ) * 1000 ;NULL );4 );0 ;0 ;NULL );
若接收到的信息是4个字节,说明server运行正常,直接返回即可。否则尝试找出错误原因并打印错误信息。
1 2 3 4 5 6 7 8 9 10 if (rlen == 4 ) {"All right - fork server is up." );return ;"Fork server handshake failed" );
小结
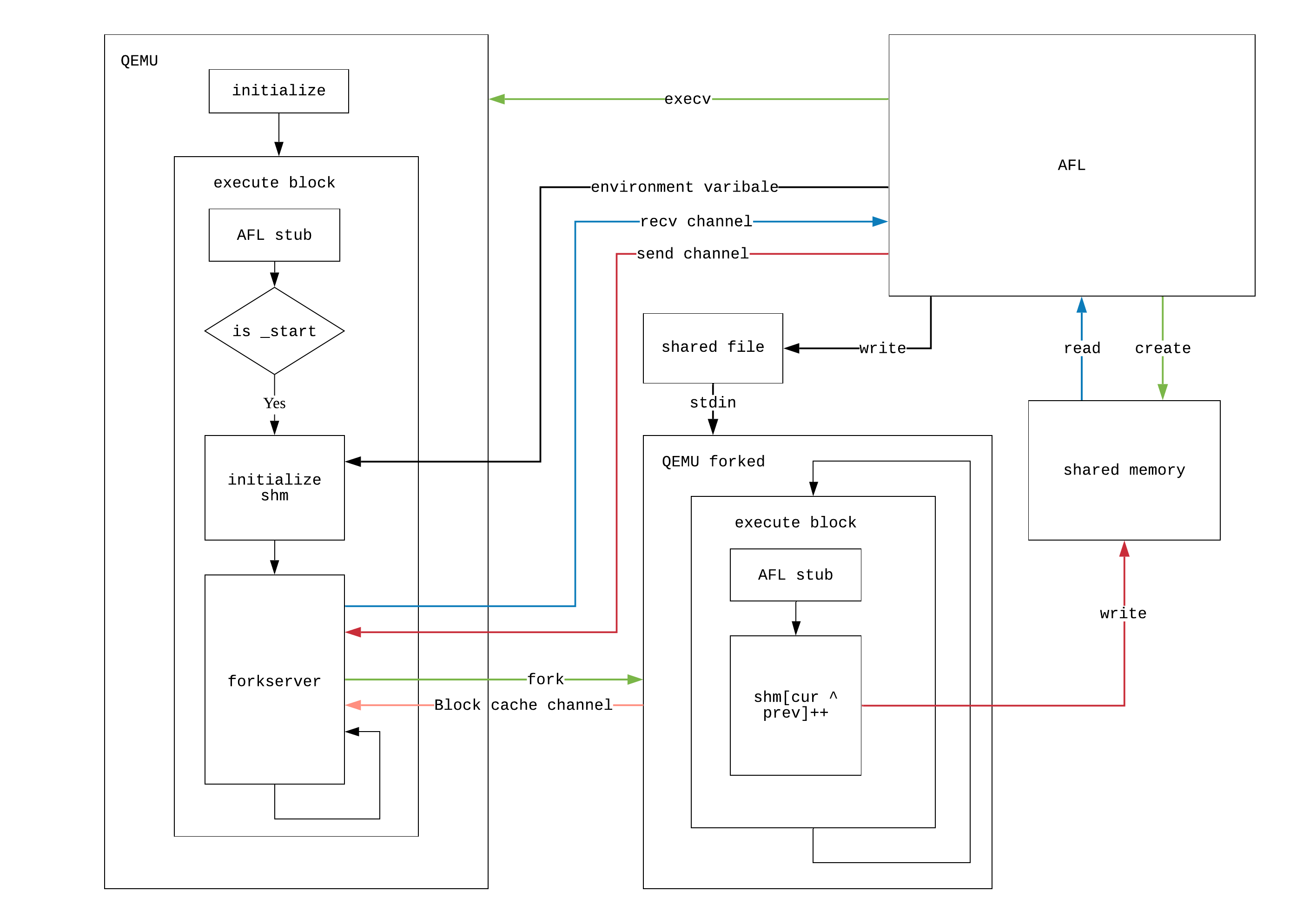
首先,我们给出forkserver架构的图示
这种方法的优越之处在于server运行在在qemu初始化阶段完成后的点,因此每次运行目标程序时不必再次初始化,大大提高了效率,同时基于server与子进程间管道的对基本块的缓存机制更是锦上添花5
至此,我们还剩下这两个未解决的问题:
AFL如何从共享数组的索引中恢复出控制流信息
覆盖率信息如何改变testcase的变异方式
首先解决第一个问题。
进行一次测试
初始化
在setup_shm函数设置共享内存的同时,它也初始化了AFL中三个特殊的数组,后面我们会看到它们的作用:
1 2 3 4 5 6 7 8 9 10 EXP_ST void setup_shm (void ) {if (!in_bitmap) memset (virgin_bits, 255 , MAP_SIZE);memset (virgin_tmout, 255 , MAP_SIZE);memset (virgin_crash, 255 , MAP_SIZE);
接下来我们开始分析AFL中用于执行一轮测试时用到的关键函数common_fuzz_stuff
该函数的参数out_buf中存放有本次测试使用的testcase,我们首先调用post_handler尝试对其进行处理(这可以是一个用户定义的函数,相当于一个插件,详情见AFL_POST_LIBRARY共享文件 写入该样例:
1 2 3 4 5 6 7 8 9 10 EXP_ST u8 common_fuzz_stuff (char ** argv, u8* out_buf, u32 len) {if (post_handler) {if (!out_buf || !len) return 0 ;
接下来调用run_target函数来执行新测试,我们很快 会分析这个函数的具体流程:
1 fault = run_target(argv, exec_tmout);
注意该函数返回值保存在fault中,这是一个枚举类型,声明如下:
1 2 3 4 5 6 7 8 enum {
经过一些看起来用处不大的流程 后,我们来到了另一个有趣的函数save_if_interesting,在这个函数中,我们对本次测试的结果进行了分析,我们很快 会分析它。
1 queued_discovered += save_if_interesting(argv, out_buf, len, fault);
最后视情况在用户界面显示统计信息:
1 2 3 4 5 if (!(stage_cur % stats_update_freq) || stage_cur + 1 == stage_max)return 0 ;
执行测试文件
当testcase准备完成后,AFL将会通过run_target函数来向forkserver发送创建新进程的请求,我们首先分析该函数的实现(只保留了forkserver模式的代码):
进行必要的初始化后,首先清空共享内存(注意上一次运行的信息已经被保存在了virgin_bits数组中,我们后面会提到)
注意一个有趣的语句MEM_BARRIER();,它的名字叫内存屏障,作用是禁止编译乱序优化,从而保证共享内存在新进程启动前已经被初始化(因为trace_bits和后面的操作没有显式的数据流依赖关系,因此鬼知道编译器会怎么优化)。
1 2 3 4 5 6 static u8 run_target (char ** argv, u32 timeout) {memset (trace_bits, 0 , MAP_SIZE);
接下来通过管道向forkserver发送开始指令,并接收从forkserver回传的新进程的pid(省略错误处理部分代码):
1 2 3 4 5 6 7 s32 res;if ((res = write(fsrv_ctl_fd, &prev_timed_out, 4 )) != 4 ) {...}if ((res = read(fsrv_st_fd, &child_pid, 4 )) != 4 ) {...}
接下来设置一个计时器并等待新进程结束执行,forkserver回传退出状态,计算新进程的执行耗费时间:
注意如果新进程超时,那么我们将触发SIGALRM信号,在AFL的初始化进程中调用了一个名为setup_signal_handlershandle_timeoutchild_timed_out置为1,然后向对应超时进程发送SIGKILL信号来终止它(forkserver向AFL进程发送子进程pid的目的)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 it.it_value.tv_sec = (timeout / 1000 );1000 ) * 1000 ;NULL );if ((res = read(fsrv_st_fd, &status, 4 )) != 4 ) {...}if (!WIFSTOPPED(status)) child_pid = 0 ;1000 +1000 );0 ;0 ;NULL );
接下来,我们更新一个全局的执行次数计数器,然后使用classify_counts
1 2 3 4 5 total_execs++;
函数classify_counts的作用很重要,它对共享内存中的每个元素mem进行如下操作:
1 2 3 4 5 6 u16* mem16 = (u16*)mem;0 ] = count_class_lookup16[mem16[0 ]];1 ] = count_class_lookup16[mem16[1 ]];2 ] = count_class_lookup16[mem16[2 ]];3 ] = count_class_lookup16[mem16[3 ]];
可以看到,它将mem拆分成四个双字节,然后分别替换为count_class_lookup16数组相应位置的值。经过进一步的研究,count_class_lookup16数组在AFL初始化进程中由init_count_class16
1 2 3 4 5 6 7 8 9 10 11 count_class_lookup16[65536 ] = 0x0000 , 0x0001 , 0x0002 , 0x0004 , 0x0008 , ... , 0x0080 ,0x0100 , 0x0101 , 0x0102 , 0x0104 , 0x0108 , ... , 0x0180 ,0x0200 , 0x0201 , 0x0202 , 0x0204 , 0x0208 , ... , 0x0280 ,0x0400 , 0x0401 , 0x0402 , 0x0404 , 0x0408 , ... , 0x0480 ,0x0800 , 0x0801 , 0x0802 , 0x0804 , 0x0808 , ... , 0x0880 ,0x0800 , 0x0801 , 0x0802 , 0x0804 , 0x0808 , ... , 0x0880 ,0x8000 , 0x8001 , 0x8002 , 0x8004 , 0x8008 , ... , 0x8080
我们知道共享内存中的单个元素大小为1字节,因此上面的操作实质上是通过双字节操作降低循环次数,最终达到的效果是将每一项中存储的hit次数对齐到了2的幂,对齐结果参考下面这一数组(数组中的每一个范围被称作一个bucket):
1 2 3 4 5 6 7 8 9 10 11 static const u8 count_class_lookup8[256 ] = {0 ] = 0 ,1 ] = 1 ,2 ] = 2 ,3 ] = 4 ,4 ... 7 ] = 8 ,8 ... 15 ] = 16 ,16 ... 31 ] = 32 ,32 ... 127 ] = 64 ,128 ... 255 ] = 128
对齐的目的我们稍后 会提到,这与覆盖率信息的解析密切相关。
最后根据情况返回新进程的测试结果,结果分为三类:正常,超时以及崩溃:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 if (WIFSIGNALED(status) && !stop_soon) {if (child_timed_out && kill_signal == SIGKILL) return FAULT_TMOUT;return FAULT_CRASH;if (!(timeout > exec_tmout) && (slowest_exec_ms < exec_ms)) {return FAULT_NONE;
覆盖率信息的提取
我们首先分析一个重要的工具函数has_new_bits。
该函数接受一个与共享内存等大的数组作为参数,然后将其中的每一项virgin与共享内存中的对应项数据current进行比较,从中提取覆盖率信息.
作为参数的统计数组在AFL中分三种,分别为virgin_bits,virgin_tmout以及virgin_crash,这三个数组内容的初始值都是0xff。每次调用has_new_bits都将更新作为参数的数组。
接下来我们明确一些称呼:
将共享内存中的数组称为共享数组
将AFL本地存储的几个用于统计的数组称为统计数组
当共享数组的某一项不为0时,我们称此项处的元组被hit(因为每一项的索引包含了一个元组的信息)
给定一个统计数组,以及一个共享数组,我们首先尝试自己设计一个算法来从中提取覆盖率信息:
已知:
统计数组和共享数组等大,每一项占一个字节
统计数组每一项的初始值都是0xff
共享数组中每一项的值是其被hit的次数,hit的次数均被对齐到了2的幂
注意第三项比较有趣,这意味着我们会打交道的hit次数都是形如1<<n的,更进一步的,是一个8位位向量的基。因此考虑利用位向量的特性来解决问题。
此时我们逐渐有了一个模糊的想法:
对于没有被hit的元组,位向量为全0,很容易过滤
对于被hit的元组,假如统计数组的对应项位向量的相应位为0,说明之前这个分支被执行过,而且这次执行的次数和之前差不多,我们认为目标程序并没有表现出新行为,也可以过滤掉
对于被hit的元组,假如统计数组的对应项位向量并非0xff,但其相应位为1,说明之前这个分支被执行过,但本次执行的次数和之前有可观的差别,我们认为目标程序表现出了新行为。
对于被hit的元组,假如统计数组的对应项位向量为0xff,说明之前这个分支没有被执行过,说明本次执行检测到了新的覆盖率。
可以看到,我们的算法已经相当完善,实际上AFL也是这么做的,只是为了加速在循环中利用类型转换一次性处理8个项。对于情形3,该函数返回1,对于情形4,返回2,否则返回0。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 static inline u8 has_new_bits (u8* virgin_map) {3 );0 ;while (i--) {if (unlikely(*current) && unlikely(*current & *virgin)) {if (likely(ret < 2 )) {if ((cur[0 ] && vir[0 ] == 0xff ) || (cur[1 ] && vir[1 ] == 0xff ) ||2 ] && vir[2 ] == 0xff ) || (cur[3 ] && vir[3 ] == 0xff ) ||4 ] && vir[4 ] == 0xff ) || (cur[5 ] && vir[5 ] == 0xff ) ||6 ] && vir[6 ] == 0xff ) || (cur[7 ] && vir[7 ] == 0xff )) 2 ;else 1 ;if (ret && virgin_map == virgin_bits) bitmap_changed = 1 ;return ret;
解析测试结果
在分析初始化进程时,我们看到了一个用于解析测试结果的函数save_if_interesting
首先看没有错误发生的情况:
crash_mode可以用命令行参数设置,默认为0,即无错误发生,此处忽略crash mode为其余值的情况。
首先利用has_new_bits检查是否有新的行为或新覆盖率,若没有,则直接退出。
1 2 3 4 5 if (fault == crash_mode) {if (!(hnb = has_new_bits(virgin_bits))) {return 0 ;
否则将产生了新覆盖率/行为的样例保存到队列中
1 2 fn = alloc_printf("%s/queue/id:%06u,%s" , out_dir, queued_paths, describe_op(hnb));0 );
若本次测试出现了新的覆盖率,则在队列中进行标示,同时更新计数器:
1 2 3 4 if (hnb == 2 ) {1 ;
接下来计算本次测试结果路径分布的哈希并保存,然后调用calibrate_case函数通过多次运行测试对本次测试进行校准(该函数同样负责对这个testcase进行打分,我们不希望受到偶发因素的影响)。若一切正常,记录该测试样例。
(我们后面会提到calibrate_case函数相关的内容
1 2 3 4 5 6 7 8 9 10 11 12 13 queue_top->exec_cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST);1 , 0 );if (res == FAULT_ERROR)"Unable to execute target application" );0600 );if (fd < 0 ) PFATAL("Unable to create '%s'" , fn);1 ;
关于覆盖率的部分到此结束,我们接下来处理目标程序可能出现的crash以及timeout:
当fault类型为超时时,我们首先对共享内存中的记录进行化简操作(被hit到的元组项赋值0x80否则赋值为0x1,然后执行has_new_bits函数。
这里has_new_bits函数的作用发生退化,其仅仅被用于判断本次运行是否与之前的超时情况重复(由于simplify_trace,hit次数被抹除),以及更新统计超时路径的数组virgin_tmout。
若本次超时访问到的分支与之前有次测试结果相同,那么判断为duplicate,直接返回。
1 2 3 4 5 6 7 8 9 10 switch (fault) {case FAULT_TMOUT:if (unique_hangs >= KEEP_UNIQUE_HANG) return keeping;if (!dumb_mode) {if (!has_new_bits(virgin_tmout)) return keeping;
执行到这个位置说明该超时case目前是唯一的。考虑到超时原因可能是timeout过短,那么上调timeout,再次运行程序,此时有三种情形
程序执行过程中产生crash
程序正常退出
程序仍然超时
对于第一种情形,我们将控制流转移到后面处理crash的部分;对于第二种情形,说明我们白忙活一场,直接返回;对于第三种情形,我们对其进行统计。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 unique_tmouts++;if (exec_tmout < hang_tmout) {if (!stop_soon && new_fault == FAULT_CRASH) goto keep_as_crash;if (stop_soon || new_fault != FAULT_TMOUT) return keeping;"%s/hangs/id:%06llu,%s" , out_dir,0 ));break ;
目标程序crash的情形与超时情形差不多,只是不必重新测试程序,不再赘述。当执行结果为FAULT_ERROR时,说明执行错误,报错并退出。其余情况下直接返回。
1 2 3 4 5 6 7 8 9 case FAULT_CRASH:case FAULT_ERROR: FATAL("Unable to execute target application" );default : return keeping;
当我们执行到这个函数的最后一部分时,说明要么发生了crash,要么发生了timeout,我们保存引起错误的testcase即可。
1 2 3 4 5 6 7 8 9 fd = open(fn, O_WRONLY | O_CREAT | O_EXCL, 0600 );if (fd < 0 ) PFATAL("Unable to create '%s'" , fn);return keeping;
小结
本节中我们了解了AFL是如何利用位向量的思想巧妙的从共享数组中提取出覆盖率信息并避免了duplicate,同时也看到了一个测试被执行后AFL对其结果的处理(保存或忽略,在产生新覆盖率时还会对当前样例进行校准打分)。
至此,我们已经解决了之前提出的大多数问题,现在只剩下一个关键问题了:覆盖率信息如何改变testcase的变异方式。我们很快会提到这一点
核心算法:遗传算法
在本节中,我们来到了AFL的核心算法:遗传算法。该算法使AFL能够从有限的测试样例中繁殖出多样的可能使程序崩溃的样例。遗传算法的几个关键点是遗传,突变,自然选择以及杂交。
不难看出,算法的客体是测试样例。我们首先给出算法所依赖的数据结构:测试样例队列:
关键数据结构
在前面的分析中,我们看到AFL实际上为testcase维护了一个队列,下面的内容很多需要操作该队列,因此我们先给出该队列的声明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 struct queue_entry {struct queue_entry *next , /* Next element , if any */ *next_100 ;
需要注意,仅当一个测试样例触发了新的覆盖率/行为时,他才会入队。
接下来我们分析算法的选择部分
选择
测试样例的评分
calibrate_case:准备工作
要选择出合适的样例,首先需要为测试样例进行评分,这一过程的准备工作在calibrate_case函数中被完成,下面分析该函数:
校准开始时先初始化一些变量,并假设本次执行失败(校准后设为成功)
1 2 3 4 5 6 7 8 9 10 static u8 calibrate_case (char ** argv, struct queue_entry* q, u8* use_mem, u32 handicap, u8 from_queue) {static u8 first_trace[MAP_SIZE];
接下来检查init_forkserver是否已启动,若没有启动,则进行初始化工作(把这一步放在这里是因为程序初始化阶段首先通过该函数测试用户提供的testcases)
1 2 if (dumb_mode != 1 && !no_forkserver && !forksrv_pid)
若该函数是一次测试后执行的,q->exec_cksum中存有本次测试得到的路径覆盖信息的哈希值,这里进行二次校验(目的何在//TODO)
1 2 3 4 5 if (q->exec_cksum) {memcpy (first_trace, trace_bits, MAP_SIZE);if (hnb > new_bits) new_bits = hnb;
接下来多次(3-8次)测试,每一轮测试中进行如下操作:
进行测试,然后计算路径覆盖信息的哈希值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 u32 cksum;if (stop_soon || fault != crash_mode) goto abort_calibration;if (!dumb_mode && !stage_cur && !count_bytes(trace_bits)) {goto abort_calibration;
若再次测试得到的哈希与原哈希不同,说明覆盖率信息发生了变化,取两次测试中表现最好的一次(has_new_bits返回值)。同时在一个统计数组var_bytes保存覆盖率发生变化的位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 if (q->exec_cksum != cksum) {if (hnb > new_bits) new_bits = hnb;if (q->exec_cksum) {for (i = 0 ; i < MAP_SIZE; i++) {if (!var_bytes[i] && first_trace[i] != trace_bits[i]) {1 ;1 ;else {memcpy (first_trace, trace_bits, MAP_SIZE);
我们通过循环花费的时间和循环的次数来计算该测试样例平均测试一次所花费的时间,结果保存到q->exec_us
1 2 3 total_cal_us += stop_us - start_us;
接下来将测试中覆盖的元组个数保存在q->bitmap_size中,并标记校准成功。更新计数器。
注意这里面的handicap,该变量描述了我们在fuzz过程中有多晚发现这个样例,发现的较晚的样例在后面 的测试中可能会被允许运行的久一点。
1 2 3 4 5 6 q->bitmap_size = count_bytes(trace_bits);0 ;
接下来调用了对测试样例进行评分的核心函数update_bitmap_score
1 2 3 update_bitmap_score(q);if (!dumb_mode && first_run && !fault && !new_bits) fault = FAULT_NOBITS;
接下来进入校准的尾声,当测试得到了新的覆盖率时,将q->has_new_cov置位,更新计数器
1 2 3 4 5 6 abort_calibration:if (new_bits == 2 && !q->has_new_cov) {1 ;
同时,如果在多次运行的过程中发现覆盖率有变化,那么将q->var_behavior置位,更新计数器
1 2 3 4 5 6 7 8 9 if (var_detected) {if (!q->var_behavior) {
update_bitmap_score:核心算法
该算法的目的在于为每一个可能的分支点找到一个
在所有样例中兼顾较短长度和较快执行速度
能覆盖到该分支
的样例。
首先计算出当前测试样例的fav_factor,这个变量指示当前的测试样例有多“好“,我们总是倾向于更短,执行更快的样例。
1 2 3 4 static void update_bitmap_score (struct queue_entry* q) {
为了为每一个可能的分支点找到最优的样例,我们维护了一个top_rated数组,数组中的项和共享内存中的项一一对应,并且指向对当前分支而言的最优测试样例(一个指向队列元素的指针)
我们需要遍历共享内存,对每一个被本样例覆盖的分支点,比较当前样例和已有的最优样例并尝试替代它。
1 2 3 4 5 6 7 8 9 10 11 for (i = 0 ; i < MAP_SIZE; i++)if (trace_bits[i]) {if (top_rated[i]) {if (fav_factor > top_rated[i]->exec_us * top_rated[i]->len) continue ;if (!--top_rated[i]->tc_ref) {0 ;
当最优样例不存在时,将本样例作为最优样例,同时尝试初始化一个本样例对应共享数组的压缩版本q->trace_mini,该数组是一个65536位的位图,它仅仅记录哪些分支被覆盖,而不关心hit
count。
1 2 3 4 5 6 7 8 9 10 11 top_rated[i] = q;if (!q->trace_mini) {3 );1 ;
选择合适的样例
测试样例的选择工作在cull_queue函数中完成,我们使用q->favored来标记一个样例是否被选中。
初始时
建立一个临时数组,数组内容初始化为0xff,该数组实际上是一个位图,容量和共享数组一致
设置所有样例的favored域为0
1 2 3 4 5 6 7 8 9 10 11 static void cull_queue (void ) {static u8 temp_v[MAP_SIZE >> 3 ];memset (temp_v, 255 , MAP_SIZE >> 3 );queue ;while (q) {0 ;
接下来我们遍历共享内存,对于每一个分支,假如其符合下面两个条件:
存在一个对应的最优样例
在已经设置为favored的样例中,没有一个能覆盖该分支
临时变量temp_v即是为了第二个条件而设置的:每找到一个符合条件的样例,对于该样例覆盖的所有分支,我们都将temp_v的对应位置0。从而使我们可以通过简单的判断验证一个分支是否满足第二个条件。
对应的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 for (i = 0 ; i < MAP_SIZE; i++)if (top_rated[i] && (temp_v[i >> 3 ] & (1 << (i & 7 )))) {3 ;while (j--) if (top_rated[i]->trace_mini[j])1 ;if (!top_rated[i]->was_fuzzed) pending_favored++;
最后,通过mark_as_redundantfs_redundant域来淘汰未被选中的样例:
1 2 3 4 5 6 7 8 q = queue ;while (q) {
至此,选择和淘汰的部分已经分析完毕,我们接下来分析遗传算法的主体。
一次fuzz的完整周期
main loop
main loop中的代码在main函数中,如下所示:
首先选择出favored cases
1 2 3 4 5 6 while (1 ) {
我们每一轮测试队列中的一个文件,但取决于测试样例的详细信息,我们也可能会跳过该文件,此处的代码相当于循环遍历待测队列,从而保证每个样例都有可能被执行到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 if (!queue_cur) {0 ;0 ;queue ;while (seek_to) {if (queued_paths == prev_queued) {if (use_splicing) cycles_wo_finds++; else use_splicing = 1 ;else cycles_wo_finds = 0 ;
接下来利用fuzz_one函数选择一个case,然后进行变异,测试,评分等一系列操作。
1 2 3 4 5 6 7 8 9 skipped_fuzz = fuzz_one(use_argv);if (!stop_soon && exit_1) stop_soon = 2 ;if (stop_soon) break ;
fuzz_one函数是整个fuzz进程的核心部分,我们下面对其进行分析
fuzz_one函数:核心部分
初始化
第一步:决定是否测试当前样例,有下面几种情况
在队列中存在尚未fuzz的样例(多个fuzzer协作的情况下可能出现这种情况)的情况下,如果当前样例已经被测试过,或者并非被选中的样例,那么有%99的概率直接返回,等待main
loop给我们队列中的下一个样例,直到找到一个没有测试过而且被选中的样例:
1 2 3 4 5 6 7 8 static u8 fuzz_one (char ** argv) {if (pending_favored) {if ((queue_cur->was_fuzzed || !queue_cur->favored) &&100 ) < SKIP_TO_NEW_PROB) return 1 ;
队列中的样例都已经测试过,但当前样例不是被选中的,同时样例的数目大于10个,那么针对已经测试过的样例,我们有%95的概率跳过他,否则有%75的概率跳过它(有点玄学)
1 2 3 4 5 6 7 8 9 else if (!dumb_mode && !queue_cur->favored && queued_paths > 10 ) {if (queue_cycle > 1 && !queue_cur->was_fuzzed) {if (UR(100 ) < SKIP_NFAV_NEW_PROB) return 1 ;else {if (UR(100 ) < SKIP_NFAV_OLD_PROB) return 1 ;
第二步:进行一些与当前样例的初始化工作
打开样例,将其映射到内存
创建一个out_buf,我们将变异后的样例存在这里
设置cur_depth,这里depth指的是从初始样例到当前样例发生变异的次数6
1 2 3 4 5 6 7 8 9 10 11 if (fd < 0 ) PFATAL("Unable to open '%s'" , queue_cur->fname);0 , len, PROT_READ | PROT_WRITE, MAP_PRIVATE, fd, 0 );0 ;
第三步:假如之前测试该样例时校准失败了,那么这里重新校准
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if (queue_cur->cal_failed) {if (queue_cur->cal_failed < CAL_CHANCES) {0 ;1 , 0 );if (res == FAULT_ERROR)"Unable to execute target application" );if (stop_soon || res != crash_mode) {goto abandon_entry;
第四步:精简当前样例,使用trim_caseout_buf。详情见该函数源码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 if (!dumb_mode && !queue_cur->trim_done) {if (stop_soon) {goto abandon_entry;1 ;if (len != queue_cur->len) len = queue_cur->len;memcpy (out_buf, in_buf, len);
q->bitmap_size),样例执行时间(q->exec_us),样例被发现的时间(q->handicap),样例从初始到现在的变异次数(q->depth)综合计算出来的值,在后面的havoc_stage中我们会看到它的作用
(在下一篇文章中介绍)
1 orig_perf = perf_score = calculate_score(queue_cur);
变异&测试
接下来进入变异和测试环节,我们首先对AFL对样例施加的变异方式进行总结:
bit flip :翻转样例中的某一位或者几位算术运算:对输入样例中的数据进行加减法等算术运算
特殊值替换:将输入样例中的数据替换为一些容易引起溢出等错误的特殊值
字典替换:使用用户提供的额外字典或自动生成的字典进行替换
havoc stage:一种非确定性的对样例进行随机变异的方式
可以看到,前四种对于一个确定的样例,其输出也是确定的,因此假如一个样例已经测试过这几项(或者用户指定不进行这些变异),我们就不再需要再次测试,这正是下面代码的用途:
1 2 3 4 5 6 7 8 if (skip_deterministic || queue_cur->was_fuzzed || queue_cur->passed_det)goto havoc_stage;if (master_max && (queue_cur->exec_cksum % master_max) != master_id - 1 )goto havoc_stage;1 ;
关于每种变异策略的详情以及字典的生成,我们会放到下一篇文章中介绍,这里暂不赘述,可以参考https://lcamtuf.blogspot.com/2014/08/binary-fuzzing-strategies-what-works.html
但我们可以给出一个典型的变异算法流程:
首先进行本类变异的准备工作:
1 2 3 4 5 6 7 stage_short = "short" ;"name" ;
然后进行变异操作,对每次变异后执行测试,测试的详细流程参见进行一次测试 ,测试的次数取决于stage_max的设置。
1 2 3 4 5 6 7 8 9 10 for (stage_cur = 0 ; stage_cur < stage_max; stage_cur++) {if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
最后对测试的结果进行统计:测试比起变异前的效果,测试的轮数
1 2 3 4 new_hit_cnt = queued_paths + unique_crashes;
小结
本节中使用到的遗传算法图示如下
至此,最后一个核心问题已经被解决,下一篇文章将会深入变异的细节。
总结
在本篇文章中,我们自下而上,基于问题来研究了AFL的实现,最后我们给出AFL的主要执行流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 int main (int argc, char ** argv) {while (1 ) {
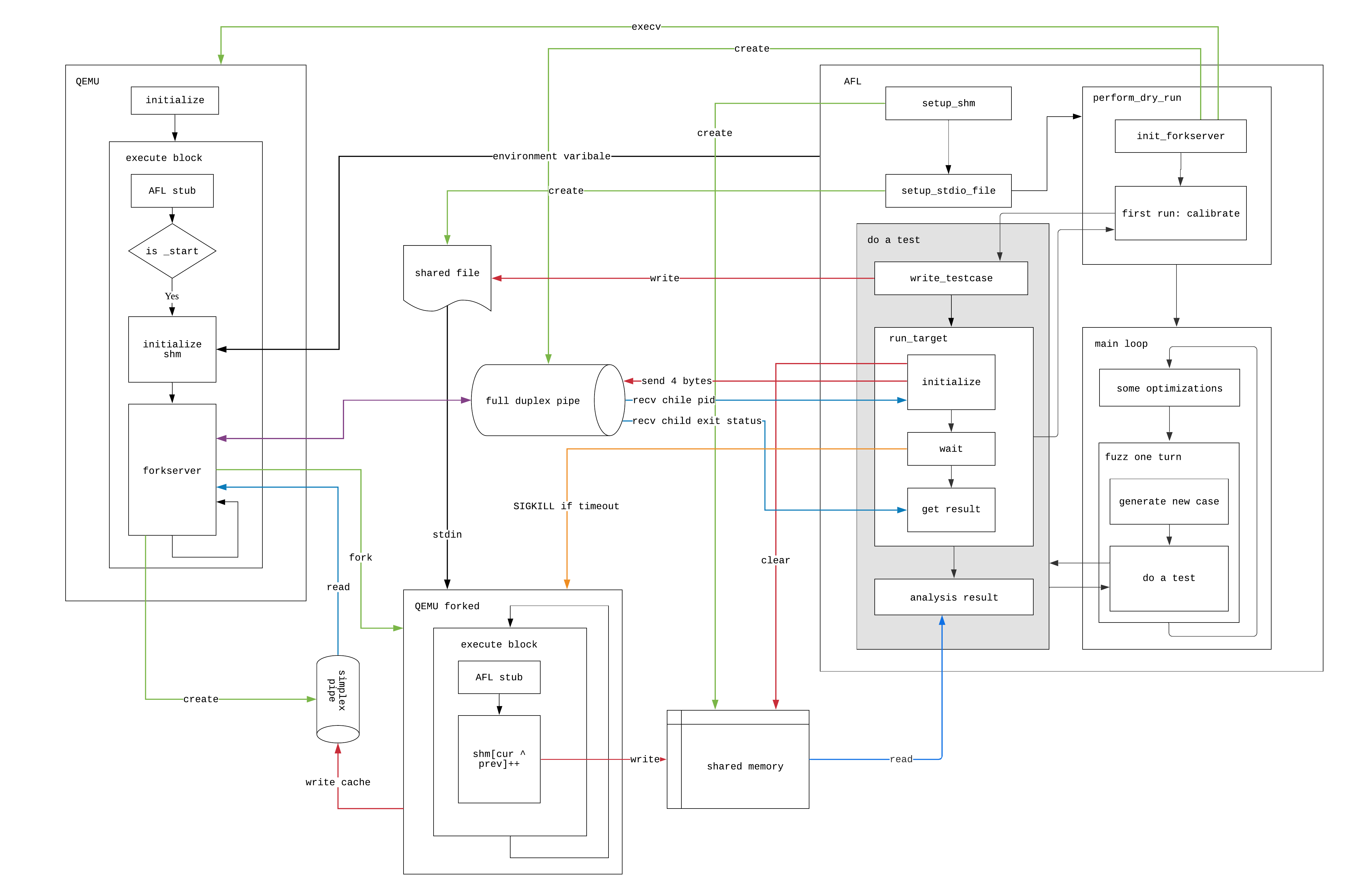
最后,我们给出一张使用QEMU mode的AFL架构图:
参考文献
[1]
[2]
[3]
[4]
[5]
[6]