静态分析基础知识
概念
SSA
静态单赋值形式(static single assignment form),即每个变量仅被赋值一次,对于下面的情形:
1 | |
可以看到x被赋值了两次,将其转换为SSA时,只需要将第二行中被赋值的x视为x的另一个版本,将其加上版本号即可,即
1 | |
但这又引起了一个问题:当两个版本的同一变量的其中一个可能在后续代码中被使用时,如何决定使用哪个,如:
1 | |
在这里,z有可能取x_3,也有可能取x_2,这时为了加以说明,我们使用一个称为Φ函数的函数,它起到这样的作用:
1 | |
在这里,Φ函数产生了一个新版本的x,这个版本的x的值由程序运行的路径动态决定。
Rice's Theorem
递归可枚举语言的所有非平凡性质都是不可判定的。
- 递归可枚举:乔姆斯基层级中的0-型语言,基本包含了目前现行的所有计算机语言
- 非平凡性质: 仅被部分递归可枚举语言所具有的性质
- 不可判定:一般意义上,可以指不存在相应的算法来对问题给出真或假的结论
program point
program point可以视为一个抽象点,比如我们认为每一个basic
block的前后有一个program
point,这个点仅仅具有形式的意义,可以为这个点附加状态(如在basic block
Must Analysis VS May Analysis
从分析的目的来看待这两个概念比较容易理解
当我们想要分析所有情况(如考虑到所有的控制流路径对一个program point带来的影响)时,我们常常在算法中进行过近似(over approximation),这时我们在做的分析称作may analysis,可以理解为求并。
当我们认为只要有一种情况无效,那么整体结论就无效(如下面提到的available expression analysis)时,我们在算法中进行欠近似(under approximation),这时我们做的分析称为must analysis,可以理解为求交。
Data Flow Analysis
这里我们先给出三个经典的data-flow analysis及其datalog实现,然后再来分析这些算法背后的数学基础。
Reaching Definition Analysis
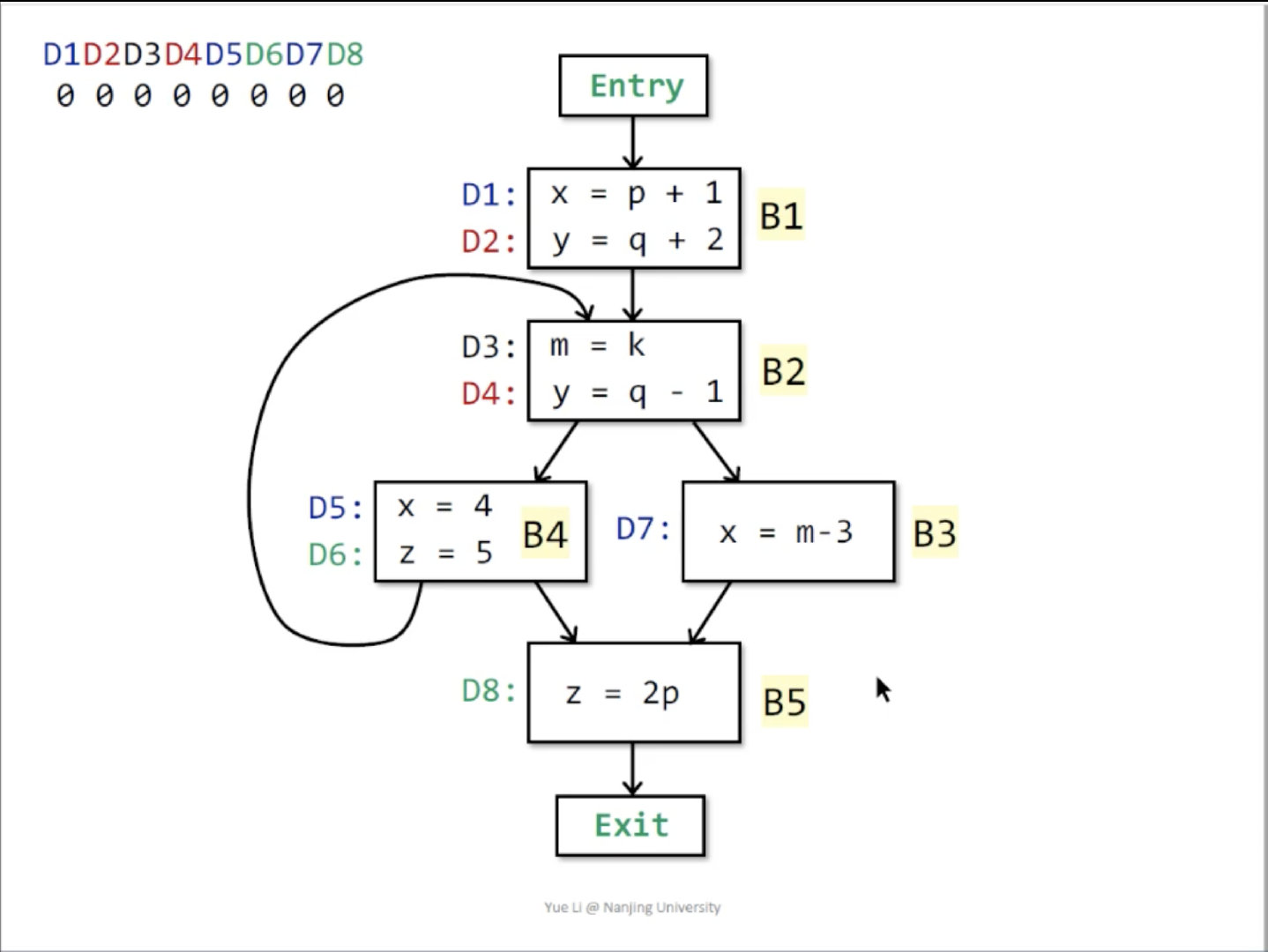
本节中我们使用下面的例子来进行分析:
问题分析
目的:对每一个变量,确定它的哪些赋值有可能通过某一个控制流路径到达过程内的任意一个特定点。
例如上面的例子,首先对问题进行建模:
- 对每一个赋值语句,我们给它一个编号
- 将每个基本块的第一条语句前和最后一条语句后视为一个
program point - 每个基本块
对应一组状态 以及 ,用于表示 之前的 program point和之后的 program point的状态 - 对每一个基本块
,有事实(facts) 以及 。对于 中的每一条赋值语句,将其放入 ,并将所有被赋值变量与该语句相同的语句放入 ,
最终我们得到下面的式子:
同时我们也指出块之间的状态传递方式,对于一个块
使用Datalog解决问题
datalog现在我们可以使用datalog来对问题进行求解,对于本问题,我们得到三个要素:
- facts:
Kill(m, n):mis basic block,nis definition.nis killed after blockmGen(m, n):mis basic block,nis definition.nis defined in blockmNext(m, n):m,nare both basic blocks.mis the precursor ofn
- outputs:
Out(m, n):nis inIn(m, n):nis in
- rules:
Out(m, n) <- Gen(m, n)//Gen中的所有定义将会进入OutOut(m, n) <- In(m, n), !Kill(m, n)// 在In中且不在Kill中的定义进入OutIn(m, n) <- Out(p, n), Next(p, m)//p为m的前驱块,则p的Out进入m的In
有了这些内容,我们便可以针对上面的问题给出对应的datalog代码,参见https://xxx/StaticAnalysis/blob/master/src/reaching_definition.rs
使用迭代算法
reaching-definition问题的本质是求取状态(program point处的definition状态)在转移函数(我们定义的
该算法必然停机的依据在于,每次遍历如果更新entry block,它是不减的,因此所有的definition的数目是有限的,因此通过上述方法来确定算法的终止是可以实现的。
进一步的,当上述“每个基本块的program points的状态也不会发生改变,因此这个算法是安全的(老师说的,存疑)。
Live Variables Analysis
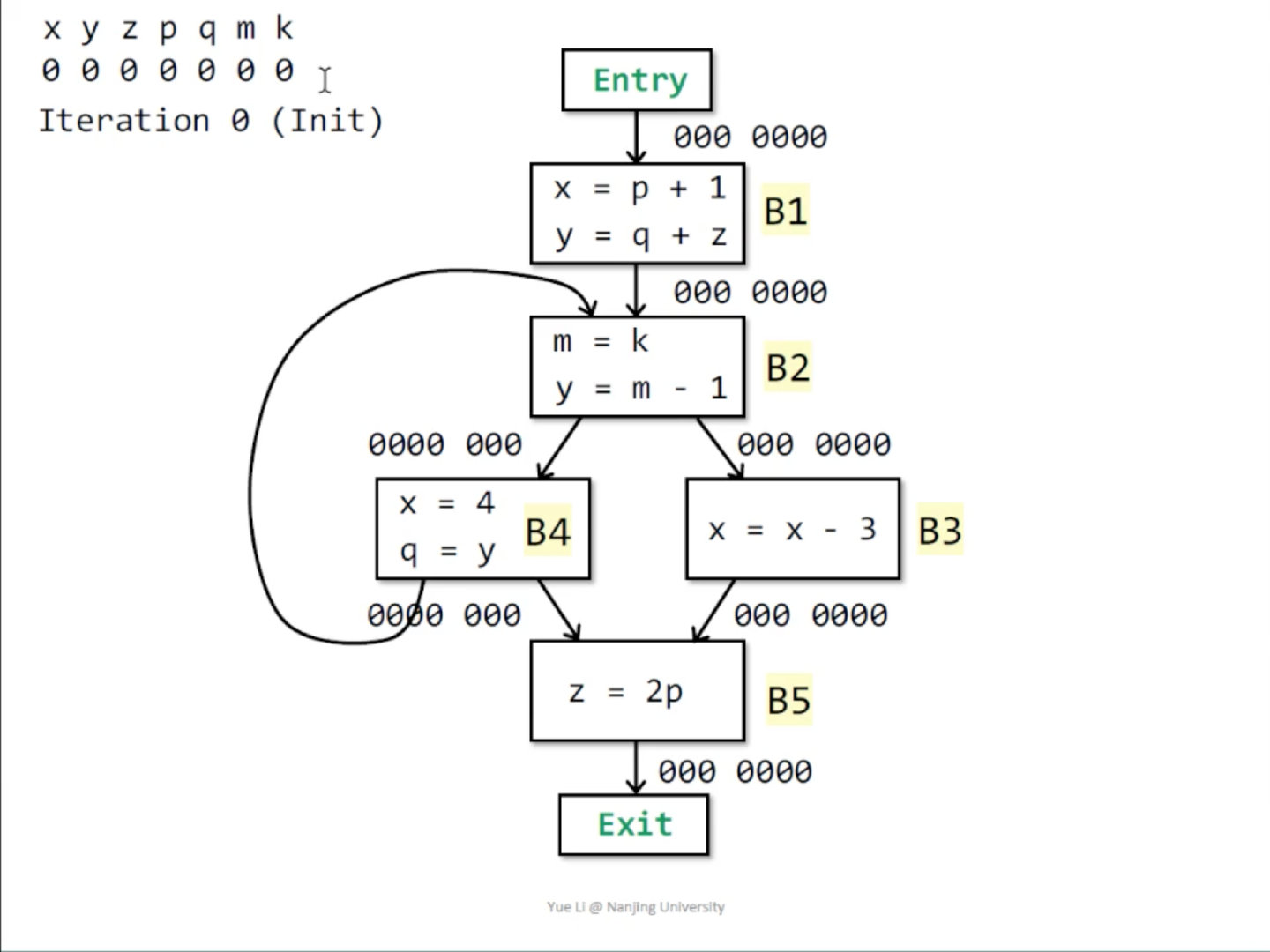
本节中使用下面的程序作为例子:
问题分析
目的:对于一个变量program point
现在对问题进行建模:
- 首先我们需要的信息可以使用一个布尔值给出,真代表变量将会被使用,即live,假代表不再使用,即dead
- 我们分析的对象是一个程序中的所有变量,因此每个
progrom point处的状态是一个位向量,每一位对应相应变量在此处的liveness - 对于一个基本块
有 fact,假设变量 在B中被重定义,即被kill掉,那么 - 对于一个基本块
有 fact,若变量 在B中被使用(如果有kill,则要求在kill之前使用),那么 - 对于每个基本块
有 和 ,分别表示该块之前和之后的 program point的状态
最终我们显然有:
同时我们也指出块之间的状态传递方式,对于一个块B,假设它有一个或者多个后继(注意我们是backward的分析)块,我们有:
使用Datalog解决问题
对于本问题,我们同样可以得到三个要素:
- facts:
Use(m, n)variablenis used in blockmKill(m, n)variablenis killed in blockmNext(m, n)blocknis the successor ofm
- outputs:
In(m, n)variablenis live at program pointOut(m, n)variablenis live at program point
- rules:
In(m, n) <- Use(m, n)In(m, n) <- Out(m, n), !Kill(m, n)Out(m, n) <- In(d, n), Next(m, d)
代码地址:https://xxx/StaticAnalysis/blob/master/src/live_variables.rs
Available Expression Analysis
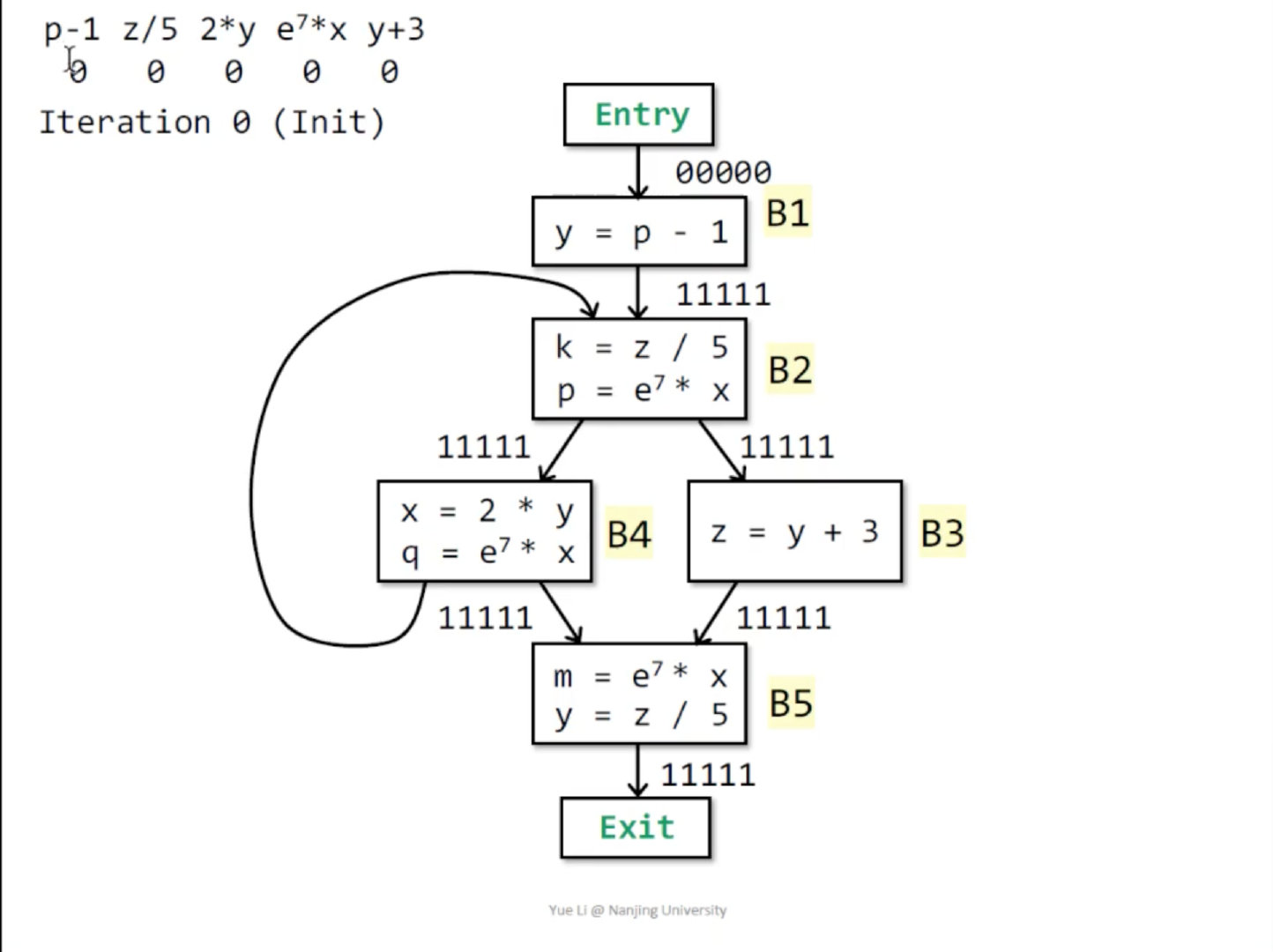
以下面的程序为例
问题分析
我们称一个expression
- 从CFG的entry block到
之间在每一条控制流路径上 都被计算 - 在每一条控制流路径上,从
被计算的点到 之间 中使用的变量都没有被重新赋值
从定义中我们可以看到,这是个must analysis,通过计算
接下来对问题进行建模:
- 对于每一个表达式,有编号
- 对于每一个基本块
有 ,若计算了 且后续没有重新定义 中的变量,则 - 对于每一个基本块有
,某语句重新定义了 中的一个变量,则 - 对于一个基本块有
,代表在 前的program point处available的 的集合 - 对于一个基本块有
,代表在 后的program point处available的 的集合
那么我们有如下关系:
使用Datalog解决问题
datalog现在我们可以使用datalog来对问题进行求解,对于本问题,我们得到三个要素:
facts:
Kill(m, n):mis basic block,nis expression.nis killed after blockmGen(m, n):mis basic block,nis expression.nis defined in blockmNext(m, n):m,nare both basic blocks.mis the precursor ofn
outputs:
Out(m, n):nis inIn(m, n):nis in
rules(暂时能用,感觉还可以再优化):
Out(m, n) <- Gen(m, n)//Gen中的所有定义将会进入OutOut(m, n) <- In(m, n), !Kill(m, n)// 在In中且不在Kill中的定义进入OutMultiPre(n) <- Next(p, n), Next(q, n), (p != q);// 基本块有多个前驱块 Intersection(n, m, b) <- Out(m, b), Out(n, b);//1
2In(n, d) <- Next(m, n), Next(p, n), Intersection(m, p, d), (m != p);
In(n, d) <- Next(m, n), !MultiPre(n), Out(m, d);
代码在这里:https://xxx/StaticAnalysis/blob/master/src/available_expression.rs
迭代算法
对于本问题,迭代算法的伪代码如下:

Foundation
本节首先给出Data flow Analysis的数学基础以及求解的一般方法。
基本概念
定义1:定义在集合
定义2:对于定义在集合
定义3:对于定义在集合
那么称
同样的,有
那么称
定义4:对于定义在集合
则称
定义5:对于定义在集合
则称
同时注意我们之后会比较关注全格中的两个特殊的元素,即
定义6:在理解了全格的概念之后,半格的概念也很容易理解,即对于定义在集合
或者
那么称
定义7:对一个格
例如定义格
定义8:对于一个格
定义9:假设有格
那么
关于不动点
我们的下面我们给出几个关于单调函数与不动点的定理:
定理1:对于一个定义在全格
证明:由
注:该证明不够严谨,更完整的证明参见Knaster–Tarski_theorem
现在我们证明了单调函数在全格上不动点的存在性,下面我们要给出一个算法来求解该不动点:
推论1:若
同样的,从
定理2:利用推论2中算法找到的不动点一定是最小不动点
证明:若存在一个不动点
又由单调性可得:
同理,如果我们从
数据流分析与格
下面我们以live variables分析为例,解析如何将上面的数学知识应用到数据流分析的设计中,回忆之前使用的CFG。
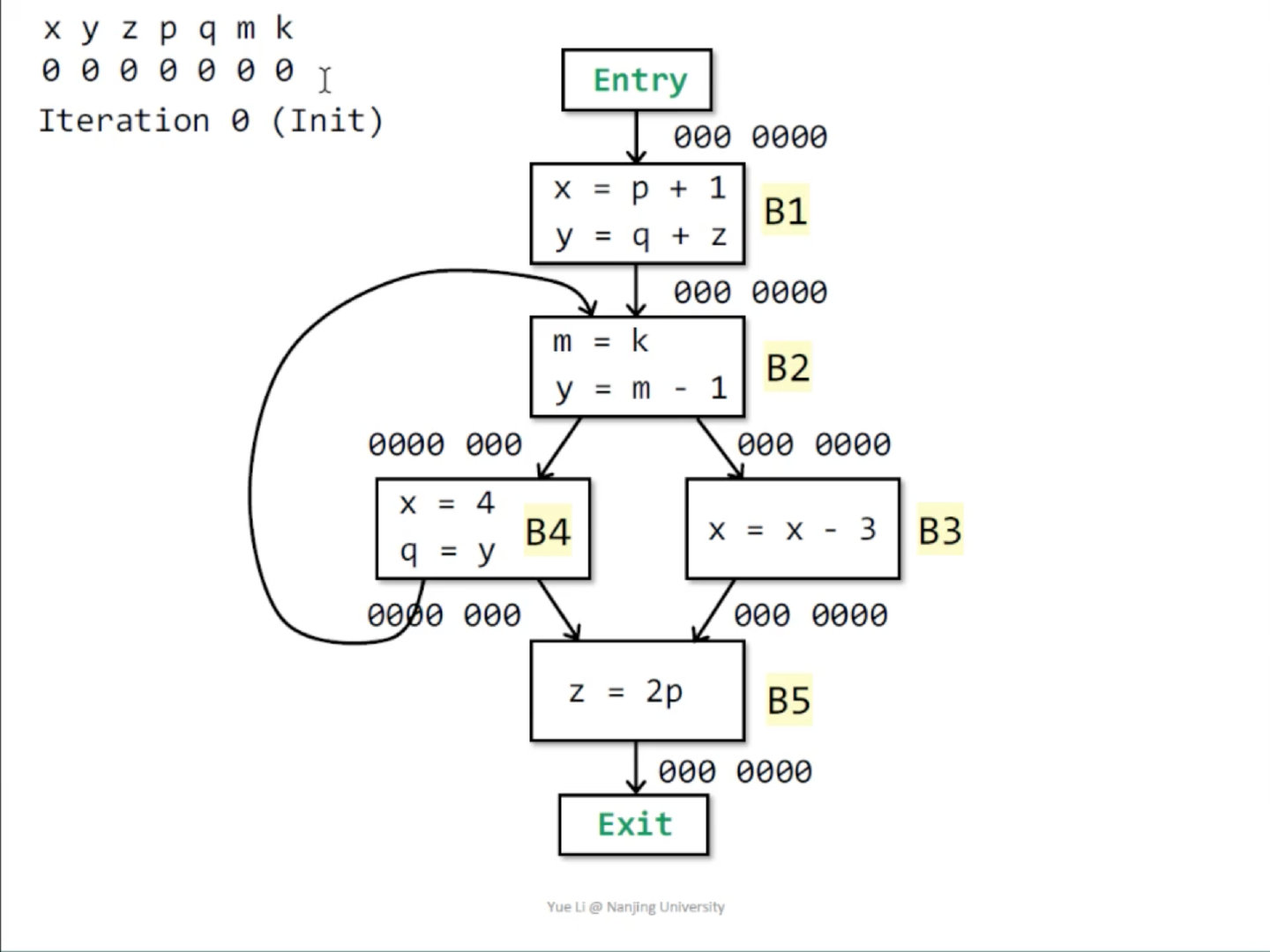
显然,每个program point都是一个格,该格的定义为
方便起见,假设变量只有
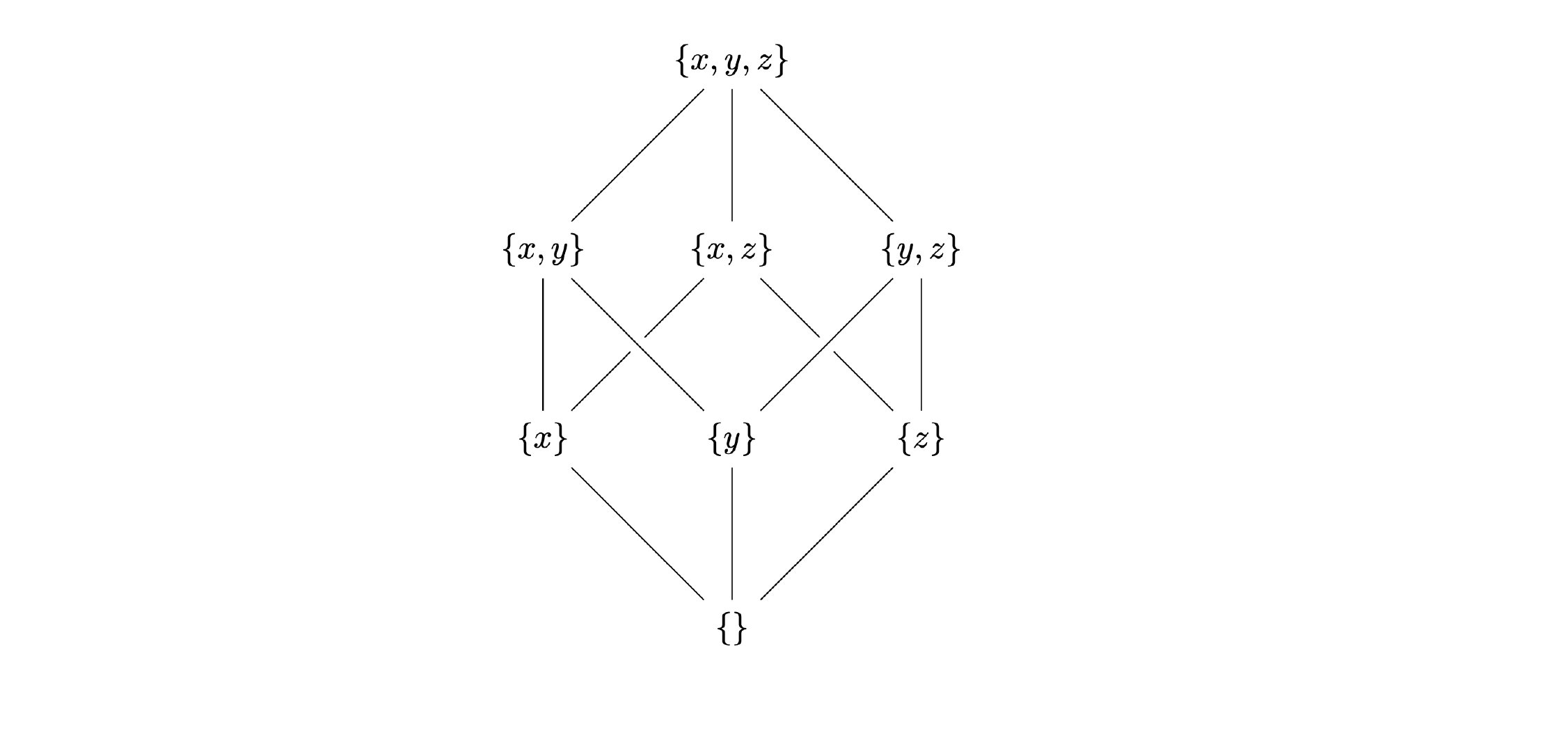
假设对于每一个基本块
该函数的第一部分可以看作一个格上的
当我们使用迭代算法进行求解时,我们的每一次遍历都相当于在格
证明
显然,转移函数
综上所述,
经过上述证明,只要我们为data flow analysis设计了良好的transfer function(满足单调性),我们可以得到如下结论:
- 通过迭代算法进行的求解一定能得到一个解(算法必然停机)
- 对于may analysis而言,初始状态是格的
,算法必然找到一个最小不动点;对于must analysis而言,初始状态是格的 ,算法必然找到一个最大不动点。
接下来,为了衡量迭代算法求出的解,我们考虑从格的角度再对may analysis以及must analysis进行分析:
再探Must Analysis与May Analysis
首先我们需要明确data flow analysis的目的,确定我们的分析结果是否是safe的,其中safe与unsafe的定义如下:
- 当我们根据data flow analysis的结果进行相应的操作,操作会带来错误的结果时,我们称分析结果是unsafe的,比如available expression分析中错误的指出某一个expression是available的,这可能会导致后续的优化出现错误,进而导致程序运行时出现非预期的结果。
- 当出现多余的操作,或者是需要进行优化的位置没有得到优化,但不会造成程序的非预期行为时,我们称结果是safe的。比如在live variables分析中指出所有的variabe都将被使用,这当然是正确的,但是会导致后续的操作变得困难(如寄存器分配难以进行)
需要注意的是,我们通过data flow analysis想要达到的目的是找到一个safe与unsafe的分界点,即truth的位置,这时我们尽可能为后续的优化提供丰富的信息,同时也避免提供错误的结果,因此我们可以通过衡量算法给出的结果与这个值的接近程度来确定算法的准确性。
下图给出了may analysis与must analysis的关系:
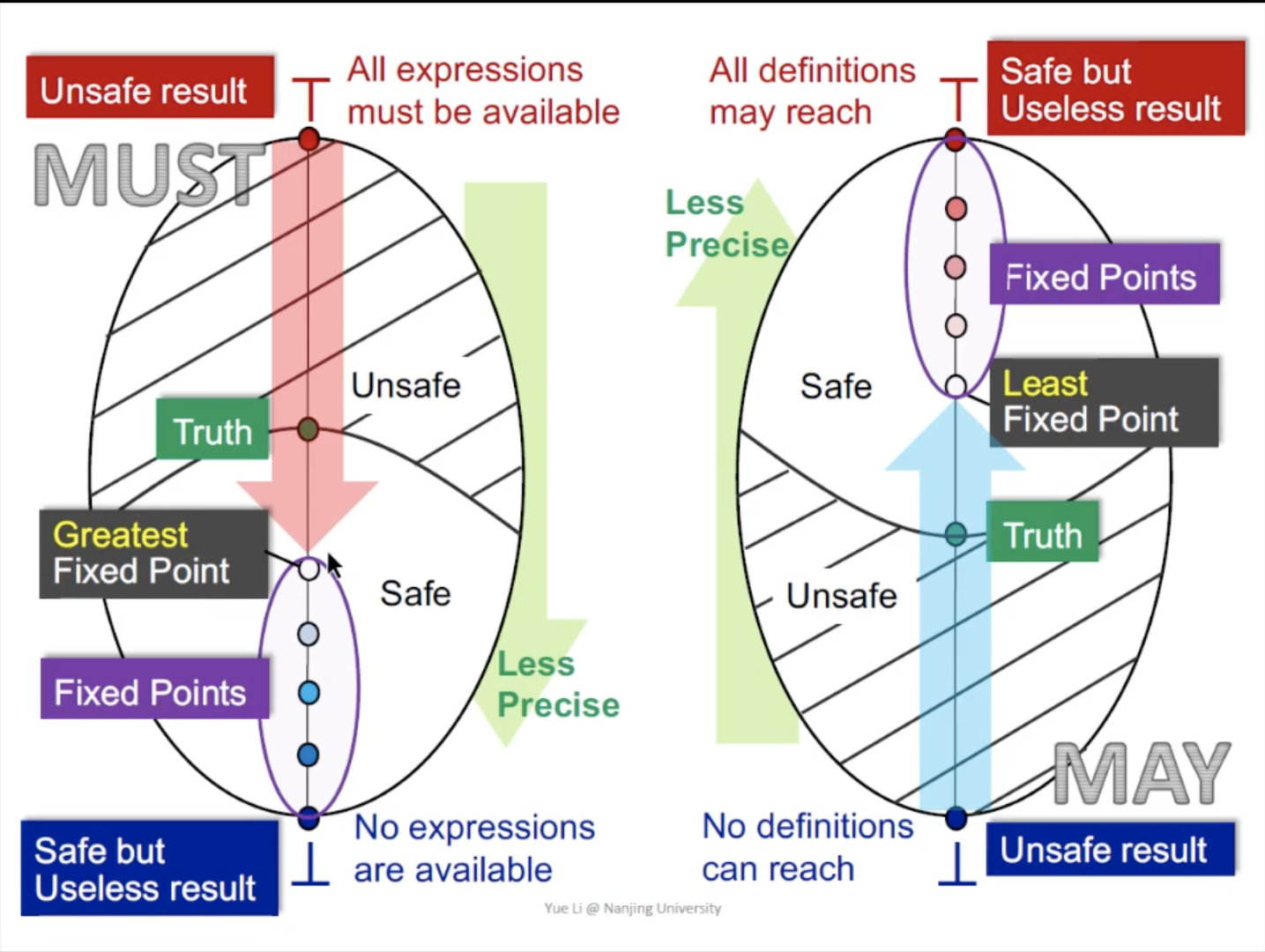
首先需要明确,算法中的转移函数
另一种方法:MOP
MOP是Meet-Over-All-Paths
solution,与上面提到的分为两部分的转移函数的设计不同的是,MOP的方法是将每个block的转移函数应用到每个前驱块的结果上,然后再进行
特别的,当我们选择的转移函数可分配时,我们的方案与MOP的转确性相同。
// TODO 添加形式化的证明
Constant Propagation Analysis
常量传播是一项非常重要的优化,首先根据上面提到的格的知识来为该问题进行建模:
- 该问题是一个forward analysis
- 定义一个包含变量所有可能取值的集合
- 每一个变量对应一个格
,该变量可以被表示为 ,这个格称为ICP,具有以下性质: - 每一条语句前后都有一个program point,此处的状态
由所有变量对应格的积组成 - 每一个block
的状态 作为特定语句前后状态的别名 - 程序的状态由每一个program point的状态的积组成
特别的,对于block