/* Defined in brk.c. */ externvoid *__curbrk; externint __brk (void *addr);
/* Extend the process's data space by INCREMENT. If INCREMENT is negative, shrink data space by - INCREMENT. Return start of new space allocated, or -1 for errors. */ void * __sbrk (intptr_t increment) { void *oldbrk;
/* If this is not part of the dynamic library or the library is used via dynamic loading in a statically linked program update __curbrk from the kernel's brk value. That way two separate instances of __brk and __sbrk can share the heap, returning interleaved pieces of it. */ if (__curbrk == NULL __libc_multiple_libcs) // 当前没有brk if (__brk (0) < 0) /* Initialize the break. */ return (void *) -1; // 初始化失败
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */ /* 当本块空闲时,存放上一个块的大小 */ INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */ /* 存放本块的总大小(有标志位“干扰”),包括头部*/
structmalloc_chunk* fd;/* double links -- used only if free. */ structmalloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */ /* 只在大块中使用,是指向下一个更大的块的指针 */ structmalloc_chunk* fd_nextsize;/* double links -- used only if free. */ structmalloc_chunk* bk_nextsize; };
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Size of previous chunk, ifunallocated(P clear) +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Size of chunk, in bytes AMP mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ User data starts here... . . . . (malloc_usable_size() bytes) . . nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ (size of chunk, but used for application data) +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Size of next chunk, in bytes A01 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Size of previous chunk, ifunallocated(P clear) +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ `head:' Size of chunk, in bytes A0P mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Forward pointer to next chunk in list +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Back pointer to previous chunk in list +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Unused space(may be 0 bytes long) . . . . nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ `foot:' Size of chunk, in bytes +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Size of next chunk, in bytes A00 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
/* A heap is a single contiguous memory region holding (coalesceable) malloc_chunks. It is allocated with mmap() and always starts at an address aligned to HEAP_MAX_SIZE. */
typedefstruct _heap_info { mstate ar_ptr; /* Arena for this heap. */ struct _heap_info *prev;/* Previous heap. */ size_t size; /* Current size in bytes. */ size_t mprotect_size; /* Size in bytes that has been mprotected PROT_READPROT_WRITE. */ /* Make sure the following data is properly aligned, particularly that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of MALLOC_ALIGNMENT. */ char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK]; } heap_info;
通过mmap直接分配,M标志位被置位的块。由于它们是逐个分配的,每个块都必须包含自己的脚部。我们会忽略一个M标志位被置位的块的其他标志位,因为它既不属于某个arena,也不会在内存中与某个空闲块相邻。The
M bit is also used for chunks which originally came from a dumped heap
via malloc_set_state in hooks.c.*(没看懂什么意思=-=)
/* Check if a request is so large that it would wrap around zero when padded and aligned. To simplify some other code, the bound is made low enough so that adding MINSIZE will also not wrap around zero. */
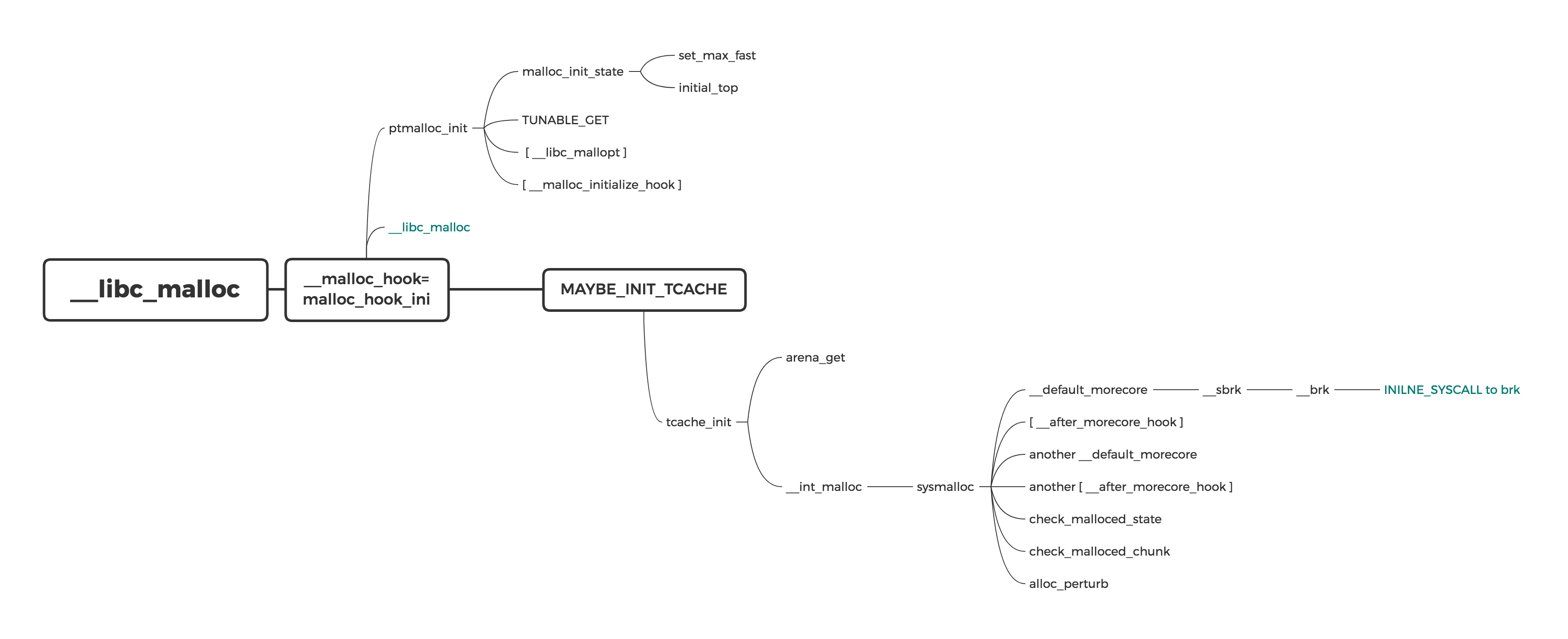
/* int __libc_mallopt (int param_number, int value) */ /* We must consolidate main arena before changing max_fast (see definition of set_max_fast). */ malloc_consolidate (av); //注意这里调用malloc_consolidate对fastbin进行了清空
switch (param_number) { case M_MXFAST: // 正如我们前面说的,M_MXFAST只是一个param_number,不太重要 if (value >= 0 && value <= MAX_FAST_SIZE) // 注意这句话真正体现出了谁才是fastbin真正的最大值(the maximum value we support) { LIBC_PROBE (memory_mallopt_mxfast, 2, value, get_max_fast ()); // 不必在意,我也不知道这个宏在做什么=-= set_max_fast (value); // 将global_max_fast设置成我们给定的值 } else res = 0; break;
Bins是一个用于存放空闲链表的数组。每个链表都是双向的。这些链表大致是按照log尺度来放置的_(如64,32,16,8在log尺度上是等距的)。这些链表一共有128个,这初看可能有点过多,但实践已经验证了它的正确性。
大多数链表中空闲块的大小可能与我们使用malloc通常会申请的堆块大小不同,但它们常常是堆中的碎片和合并后的堆块的大小。以正因此,我们可以更快捷的进行查找。
我们维护着这样一个不变的事实:任何一个被合并后的堆块从物理上不与另一个相邻(即空闲块不相邻)。因此链表中的每个块要么是与已分配的块相邻。要么是位于可用的堆空间的尽头。
bins的链表中的块是按照大小来组织顺序的,链表的末端近似是距上次使用时间最久的块。对于small
bins来说,顺序不是必须的,因为small
bins的链表中的每个块大小相等(还记得我们的堆的理论基础吗?这属于基于大小类的简单分离存储策略)。然而对于较大的块的分类来说,顺序可以加快最佳适配的速度。These
lists are just sequential. Keeping them in order almost never requires
enough traversal to warrant using fancier ordered data
structures.(完全不会翻译=-=)_
在链接在一起的同等大小的块中,最近释放的块被排在最前面,而分配的块则会从链表的尾部取。即FIFO的分配顺序_(可以理解为一个链队),这样可以保证每个块具有同等的机会和相邻的空闲块合并,从而达成空闲块尽可能大,碎片尽可能少的目的。(可否添加更详细的解释?)_
为了简化对双向链表的操作,每个bin的头部可以被当作malloc_chunk类型的数据使用。这避免了头部带来的特殊情况。但为了节省空间并增强局部性,我们仅仅为bins的头部分配fd与bk指针,然后使用一些tricks来把它们作为malloc_chunk的元素来看待。(记住这一点,下面有大用处)你可能会问,哪里增强局部性了?下面是笔者的一点看法:假设我们使用amd64平台,那么一个完整的malloc_chunk的大小是48个字节。回顾我们学习的有关cache的知识,一个cache行可能是64字节或者32字节,这并不是48的倍数。这意味着当我们使用交替使用相邻的两块bin的头部的数据时,这些数据并不能很好的被放置到cache
line中,在最坏的情况下甚至可能发生抖动。而当头部仅仅为两个指针,即16byte时,我们访问一个bin的头部之后可以保证与其相邻的4个bin的头部信息都完整的缓存到了cache中。这大大提升了访问局部数据的速度
(太妙了)
64 bins of size 8 32 bins of size 64 16 bins of size 512 8 bins of size 4096 4 bins of size 32768 2 bins of size 262144 1 bin of size what's left
为了速度,bin_index中的数字其实要稍大一点。但这没什么影响。(需要更详细的解释)
bins中的块最大在1MB左右,因为我们假设更大的块是通过mmap来分配的。
索引为0的bin不存在,索引为1的bin是无序的链表。if that would be a valid
chunk size the small bins are bumped up one._(不会翻译=-=)_
bin_at
1 2 3 4
/* addressing -- note that bin_at(0) does not exist */ #define bin_at(m, i) \ (mbinptr) (((char *) &((m)->bins[((i) - 1) * 2])) \ - offsetof (struct malloc_chunk, fd))
最上面的那个空闲块(位于可访问的内存的尽头,即top)是被特殊对待的。它从来不被任何bin包含在内,只有当没有其他空闲块可用时,它才会派上用场。同时当top非常大时会被归还给操作系统(见M_TRIM_THRESHOLD)。
Because top initially points to its own bin with initial zero size, thus
forcing extension on the first malloc request, we avoid having any
special code in malloc to check whether it even exists yet. But we still
need to do so when getting memory from system, so we make initial_top
treat the bin as a legal but unusable chunk during the interval between
initialization and the first call to sysmalloc. (This is somewhat
delicate, since it relies on the 2 preceding words to be zero during
this interval as well.)
1 2
/* Conveniently, the unsorted bin can be used as dummy top on first call */ #define initial_top(M) (unsorted_chunks (M))
/* Conservatively use 32 bits per map word, even if on 64bit system */ #define BINMAPSHIFT 5 #define BITSPERMAP (1U << BINMAPSHIFT) #define BINMAPSIZE (NBINS / BITSPERMAP)
/* With rounding and alignment, the bins are... idx 0 bytes 0..24 (64-bit) or 0..12 (32-bit) idx 1 bytes 25..40 or 13..20 idx 2 bytes 41..56 or 21..28 etc. */
/* This is another arbitrary limit, which tunables can change. Each tcache bin will hold at most this number of chunks. */
/* mmap支持 */ int n_mmaps; int n_mmaps_max; // 指定了同一时间最大使用mmap的请求数(即同一时间有多少个mmap块存在) int max_n_mmaps; /* 在用户显式的设置 trim_threshold,top_pad,mmap_threshold,max_n_mmaps 这几个变量之前,它们的值是动态的。对这些变量的显式设置会导致no_dyn_threshold被置位*/ int no_dyn_threshold;
/* list_lock prevents concurrent writes to the next member of struct malloc_state objects.
Read access to the next member is supposed to synchronize with the atomic_write_barrier and the write to the next member in _int_new_arena. This suffers from data races; see the FIXME comments in _int_new_arena and reused_arena.
list_lock also prevents concurrent forks. At the time list_lock is acquired, no arena lock must have been acquired, but it is permitted to acquire arena locks subsequently, while list_lock is acquired. */ __libc_lock_define_initialized (static, list_lock);
#ifdef SHARED /* In case this libc copy is in a non-default namespace, never use brk. Likewise if dlopened from statically linked program. */ Dl_info di; structlink_map *l;
while (__builtin_expect ((envline = next_env_entry (&runp)) != NULL, 0)) { size_t len = strcspn (envline, "=");
if (envline[len] != '=') /* This is a "MALLOC_" variable at the end of the string without a '=' character. Ignore it since otherwise we will access invalid memory below. */ continue;
/* Add the new arena to the global list. */ a->next = main_arena.next; /* FIXME: The barrier is an attempt to synchronize with read access in reused_arena, which does not acquire list_lock while traversing the list. */ atomic_write_barrier (); /* 这是一个写屏障,展开后的形式是asm volatile ("" : : : "memory") * 作用是保证程序编译是屏障两侧操作的有序性,否则有可能出现main_arena.next先被赋值为a, * 但a的next域并未指向原main_arena.next的情况,导致另外一个线程的reuse_arena在遍历 * 该循环链表时出现segmentation fault。*/ main_arena.next = a;
/* Lock this arena. NB: Another thread may have been attached to this arena because the arena is now accessible from the main_arena.next list and could have been picked by reused_arena. This can only happen for the last arena created (before the arena limit is reached). At this point, some arena has to be attached to two threads. We could acquire the arena lock before list_lock to make it less likely that reused_arena picks this new arena, but this could result in a deadlock with __malloc_fork_lock_parent. */
/* 获取一个可以被重复利用用来分配内存的arena并将其上锁,避免分配到avoid_arena,因为我们 * 尝试过在那里分配空间而且失败了 */ static mstate reused_arena(mstate avoid_arena) { mstate result; /* FIXME: Access to next_to_use suffers from data races. */ static mstate next_to_use; if (next_to_use == NULL) next_to_use = &main_arena;
/* Iterate over all arenas (including those linked from free_list). */ result = next_to_use; do { if (!__libc_lock_trylock (result->mutex)) goto out;
/* FIXME: This is a data race, see _int_new_arena. */ result = result->next; } while (result != next_to_use);
/* Avoid AVOID_ARENA as we have already failed to allocate memory in that arena and it is currently locked. */ if (result == avoid_arena) result = result->next;
/* No arena available without contention. Wait for the next in line. */ LIBC_PROBE (memory_arena_reuse_wait, 3, &result->mutex, result, avoid_arena); __libc_lock_lock (result->mutex);
out: /* Attach the arena to the current thread. */ { /* Update the arena thread attachment counters. */ mstate replaced_arena = thread_arena; __libc_lock_lock (free_list_lock); detach_arena (replaced_arena);
/* We may have picked up an arena on the free list. We need to preserve the invariant that no arena on the free list has a positive attached_threads counter (otherwise, arena_thread_freeres cannot use the counter to determine if the arena needs to be put on the free list). We unconditionally remove the selected arena from the free list. The caller of reused_arena checked the free list and observed it to be empty, so the list is very short. */ remove_from_free_list (result);
if (ar_ptr != NULL) __libc_lock_unlock (ar_ptr->mutex);
/* In a low memory situation, we may not be able to allocate memory - in which case, we just keep trying later. However, we typically do this very early, so either there is sufficient memory, or there isn't enough memory to do non-trivial allocations anyway. */ if (victim) { tcache = (tcache_perthread_struct *) victim; memset (tcache, 0, sizeof (tcache_perthread_struct)); }
staticvoid * sysmalloc(INTERNAL_SIZE_T nb, mstate av) { mchunkptr old_top; /* incoming value of av->top */ INTERNAL_SIZE_T old_size; /* its size */ char *old_end; /* its end address */
long size; /* arg to first MORECORE or mmap call */ char *brk; /* return value from MORECORE */
long correction; /* arg to 2nd MORECORE call */ char *snd_brk; /* 2nd return val */
INTERNAL_SIZE_T front_misalign; /* unusable bytes at front of new space */ INTERNAL_SIZE_T end_misalign; /* partial page left at end of new space */ char *aligned_brk; /* aligned offset into brk */
mchunkptr p; /* the allocated/returned chunk */ mchunkptr remainder; /* remainder from allocation */ unsignedlong remainder_size; /* its size */
if (mm != MAP_FAILED) { /* The offset to the start of the mmapped region is stored in the prev_size field of the chunk. This allows us to adjust returned start address to meet alignment requirements here and in memalign(), and still be able to compute proper address argument for later munmap in free() and realloc(). */
/* Setup fencepost and free the old top chunk with a multiple of MALLOC_ALIGNMENT in size. */ /* The fencepost takes at least MINSIZE bytes, because it might become the top chunk again later. Note that a footer is set up, too, although the chunk is marked in use. */ old_size = (old_size - MINSIZE) & ~MALLOC_ALIGN_MASK; set_head (chunk_at_offset (old_top, old_size + 2 * SIZE_SZ), 0 PREV_INUSE); if (old_size >= MINSIZE) { set_head (chunk_at_offset (old_top, old_size), (2 * SIZE_SZ) PREV_INUSE); set_foot (chunk_at_offset (old_top, old_size), (2 * SIZE_SZ)); set_head (old_top, old_size PREV_INUSE NON_MAIN_ARENA); _int_free (av, old_top, 1); } else { set_head (old_top, (old_size + 2 * SIZE_SZ) PREV_INUSE); set_foot (old_top, (old_size + 2 * SIZE_SZ)); } } elseif (!tried_mmap) /* We can at least try to use to mmap memory. */ goto try_mmap; } else/* av == main_arena */ /* 下面这一段需要我们重点关注,它是main_arena初始化工作的尾声,在这一部分结束后 * 我们的进程地址空间中才真正出现了可以用来分配内存的main_arena */
{ /* Request enough space for nb + pad + overhead */ size = nb + mp_.top_pad + MINSIZE;
* If there was an intervening foreign sbrk, we need to adjust sbrk request size to account for fact that we will not be able to combine new space with existing space in old_top.
/* 利用最佳适配原则从最近释放的块和remainder中取出一个块。例外情况是if this a small request, * the chunk is remainder from the most recent non-exact fit. * 将遍历过的chunk依照大小放在bins中。注意这是唯一一个chunk可以被放到bins里面的机会 。*/
for (;; ) { /* 若本block的余下部分都没有有效的bin,那么跳过整个block */ if (bit > map bit == 0) { do { if (++block >= BINMAPSIZE) /* out of bins */ goto use_top; } while ((map = av->binmap[block]) == 0);
bin = bin_at (av, (block << BINMAPSHIFT)); bit = 1; } // 通过上面这个if语句,我们可以确定现在这个bin所在的block中必然有一个bin是有效的
/* 我们使用这个循环来找到那个有效的bin */ while ((bit & map) == 0) { bin = next_bin (bin); bit <<= 1; assert (bit != 0); }
/* 检查这个bin,它有可能是空的(我们之前说过,当一个bin为空时,它对应的binmap项并不会立即被clear) */ victim = last (bin); /* 注意这里的last体现了先进先出原则,bins实际上可以看作是由双向循环链表模拟的队列 */
/* 如果这个bin是空的,那么将其对应的binmap项clear,然后进入下一次for循环 */ if (victim == bin) { av->binmap[block] = map &= ~bit; bin = next_bin (bin); bit <<= 1; }
victim = _int_malloc (ar_ptr, bytes); /* Retry with another arena only if we were able to find a usable arena before. */ if (!victim && ar_ptr != NULL) { LIBC_PROBE (memory_malloc_retry, 1, bytes); ar_ptr = arena_get_retry (ar_ptr, bytes); victim = _int_malloc (ar_ptr, bytes); }
if (ar_ptr != NULL) __libc_lock_unlock (ar_ptr->mutex);
/* Can this heap go away completely? */ while (top_chunk == chunk_at_offset (heap, sizeof (*heap))) { prev_heap = heap->prev; prev_size = prev_heap->size - (MINSIZE - 2 * SIZE_SZ); p = chunk_at_offset (prev_heap, prev_size); /* fencepost must be properly aligned. */ misalign = ((long) p) & MALLOC_ALIGN_MASK; p = chunk_at_offset (prev_heap, prev_size - misalign); assert (chunksize_nomask (p) == (0 PREV_INUSE)); /* must be fencepost */ p = prev_chunk (p); new_size = chunksize (p) + (MINSIZE - 2 * SIZE_SZ) + misalign; assert (new_size > 0 && new_size < (long) (2 * MINSIZE)); if (!prev_inuse (p)) new_size += prev_size (p); assert (new_size > 0 && new_size < HEAP_MAX_SIZE); if (new_size + (HEAP_MAX_SIZE - prev_heap->size) < pad + MINSIZE + pagesz) break; ar_ptr->system_mem -= heap->size; LIBC_PROBE (memory_heap_free, 2, heap, heap->size); delete_heap (heap); heap = prev_heap; if (!prev_inuse (p)) /* consolidate backward */ { p = prev_chunk (p); unlink_chunk (ar_ptr, p); } assert (((unsignedlong) ((char *) p + new_size) & (pagesz - 1)) == 0); assert (((char *) p + new_size) == ((char *) heap + heap->size)); top (ar_ptr) = top_chunk = p; set_head (top_chunk, new_size PREV_INUSE); /*check_chunk(ar_ptr, top_chunk);*/ }
/* Uses similar logic for per-thread arenas as the main arena with systrim and _int_free by preserving the top pad and rounding down to the nearest page. */ top_size = chunksize (top_chunk); if ((unsignedlong)(top_size) < (unsignedlong)(mp_.trim_threshold)) return0;
staticvoid _int_free (mstate av, mchunkptr p, int have_lock) { INTERNAL_SIZE_T size; /* its size */ mfastbinptr *fb; /* associated fastbin */ mchunkptr nextchunk; /* next contiguous chunk */ INTERNAL_SIZE_T nextsize; /* its size */ int nextinuse; /* true if nextchunk is used */ INTERNAL_SIZE_T prevsize; /* size of previous contiguous chunk */ mchunkptr bck; /* misc temp for linking */ mchunkptr fwd; /* misc temp for linking */
size = chunksize (p);
/* Little security check which won't hurt performance: the allocator never wrapps around at the end of the address space. Therefore we can exclude some size values which might appear here by accident or by "design" from some intruder. */ if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0) __builtin_expect (misaligned_chunk (p), 0)) malloc_printerr ("free(): invalid pointer"); /* We know that each chunk is at least MINSIZE bytes in size or a multiple of MALLOC_ALIGNMENT. */ if (__glibc_unlikely (size < MINSIZE !aligned_OK (size))) malloc_printerr ("free(): invalid size");
check_inuse_chunk(av, p);
#if USE_TCACHE { size_t tc_idx = csize2tidx (size); if (tcache != NULL && tc_idx < mp_.tcache_bins) { /* Check to see if it's already in the tcache. */ tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* This test succeeds on double free. However, we don't 100% trust it (it also matches random payload data at a 1 in 2^<size_t> chance), so verify it's not an unlikely coincidence before aborting. */ if (__glibc_unlikely (e->key == tcache)) { tcache_entry *tmp; LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx); for (tmp = tcache->entries[tc_idx]; tmp; tmp = tmp->next) if (tmp == e) malloc_printerr ("free(): double free detected in tcache 2"); /* If we get here, it was a coincidence. We've wasted a few cycles, but don't abort. */ }
/* If eligible, place chunk on a fastbin so it can be found and used quickly in malloc. */
if ((unsignedlong)(size) <= (unsignedlong)(get_max_fast ())
#if TRIM_FASTBINS /* If TRIM_FASTBINS set, don't place chunks bordering top into fastbins */ && (chunk_at_offset(p, size) != av->top) #endif ) {
if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size)) <= 2 * SIZE_SZ, 0) __builtin_expect (chunksize (chunk_at_offset (p, size)) >= av->system_mem, 0)) { bool fail = true; /* We might not have a lock at this point and concurrent modifications of system_mem might result in a false positive. Redo the test after getting the lock. */ if (!have_lock) { __libc_lock_lock (av->mutex); fail = (chunksize_nomask (chunk_at_offset (p, size)) <= 2 * SIZE_SZ chunksize (chunk_at_offset (p, size)) >= av->system_mem); __libc_lock_unlock (av->mutex); }
if (fail) malloc_printerr ("free(): invalid next size (fast)"); }
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */ mchunkptr old = *fb, old2;
if (SINGLE_THREAD_P) { /* Check that the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect (old == p, 0)) malloc_printerr ("double free or corruption (fasttop)"); p->fd = old; *fb = p; } else do { /* Check that the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect (old == p, 0)) malloc_printerr ("double free or corruption (fasttop)"); p->fd = old2 = old; } while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2)) != old2);
/* Check that size of fastbin chunk at the top is the same as size of the chunk that we are adding. We can dereference OLD only if we have the lock, otherwise it might have already been allocated again. */ if (have_lock && old != NULL && __builtin_expect (fastbin_index (chunksize (old)) != idx, 0)) malloc_printerr ("invalid fastbin entry (free)"); }
/* Consolidate other non-mmapped chunks as they arrive. */
elseif (!chunk_is_mmapped(p)) {
/* If we're single-threaded, don't lock the arena. */ if (SINGLE_THREAD_P) have_lock = true;
if (!have_lock) __libc_lock_lock (av->mutex);
nextchunk = chunk_at_offset(p, size);
/* Lightweight tests: check whether the block is already the top block. */ if (__glibc_unlikely (p == av->top)) malloc_printerr ("double free or corruption (top)"); /* Or whether the next chunk is beyond the boundaries of the arena. */ if (__builtin_expect (contiguous (av) && (char *) nextchunk >= ((char *) av->top + chunksize(av->top)), 0)) malloc_printerr ("double free or corruption (out)"); /* Or whether the block is actually not marked used. */ if (__glibc_unlikely (!prev_inuse(nextchunk))) malloc_printerr ("double free or corruption (!prev)");
/* Place the chunk in unsorted chunk list. Chunks are not placed into regular bins until after they have been given one chance to be used in malloc. */
/* If freeing a large space, consolidate possibly-surrounding chunks. Then, if the total unused topmost memory exceeds trim threshold, ask malloc_trim to reduce top.
Unless max_fast is 0, we don't know if there are fastbins bordering top, so we cannot tell for sure whether threshold has been reached unless fastbins are consolidated. But we don't want to consolidate on each free. As a compromise, consolidation is performed if FASTBIN_CONSOLIDATION_THRESHOLD is reached. */
if ((unsignedlong)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) { if (atomic_load_relaxed (&av->have_fastchunks)) malloc_consolidate(av);
if (av == &main_arena) { #ifndef MORECORE_CANNOT_TRIM if ((unsignedlong)(chunksize(av->top)) >= (unsignedlong)(mp_.trim_threshold)) systrim(mp_.top_pad, av); #endif } else { /* Always try heap_trim(), even if the top chunk is not large, because the corresponding heap might go away. */ heap_info *heap = heap_for_ptr(top(av));
staticvoidmalloc_consolidate(mstate av) { mfastbinptr* fb; /* current fastbin being consolidated */ mfastbinptr* maxfb; /* last fastbin (for loop control) */ mchunkptr p; /* current chunk being consolidated */ mchunkptr nextp; /* next chunk to consolidate */ mchunkptr unsorted_bin; /* bin header */ mchunkptr first_unsorted; /* chunk to link to */
/* These have same use as in free() */ mchunkptr nextchunk; INTERNAL_SIZE_T size; INTERNAL_SIZE_T nextsize; INTERNAL_SIZE_T prevsize; int nextinuse;