updated:
非递归汉诺塔 - 实验报告
实验要求
实验目的
理解利用堆栈以非递归方式实现一些递归函数的方法。
实验内容
借助堆栈以非递归(循环)方式求解汉诺塔的问题(n,a,b,e),即将n个盘子从起始柱(标记为“a”)通过借助柱(标记为“b")移动到目标柱(标记为“c"),并保证每个移动符合汉诺塔问题的要求。
程序设计
数据结构设计
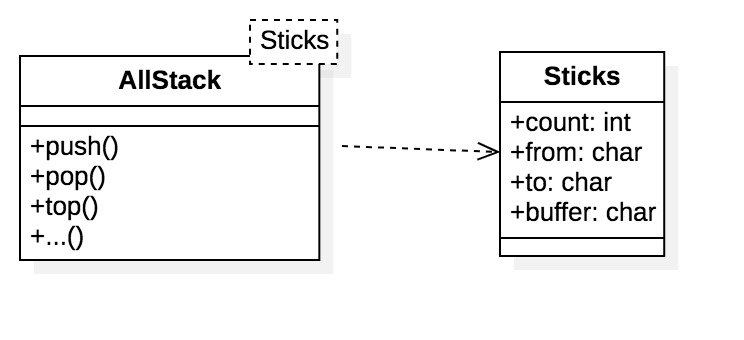
关键算法分析
问题的关键在于模拟递归,那么就要模拟递归的几个要素:
- 结束条件
- 栈结构
对于栈结构来说,通过移走当前问题顶端 \(n - 1\) 个圆盘来将其分解为一个 \(n - 1\) 的问题和一个 \(1\) 的问题,然后将其分别压栈,压栈分三步,代表两个问题和一个阶段:
- 将顶端的 \(n - 1\) 个盘子从原from,以原来的to作为buffer移到原buffer。
- 将剩下的一个盘子从原from移到原to。
- 将“将 \(n - 1\) 个盘子从原buffer移到原to作为新问题压栈,在下一次循环中出栈并再次分解。
程序测试结果
测试流程图
main -> hanoi
测试数据
1 2 3
测试结果
input
output
1
a -> c
2
a -> b
a -> c
b -> c
3
a -> c
a -> b
c -> b
a -> c
b -> a
b -> c
a -> c
结果分析
符合预期
思考题
本题实现的非递归程序实际上是在用堆栈模仿递归程序的实现过程。可以同时比较非递归和递归程序在不同问题规模下的运行时间,两者是否有很大差别?为什么?
进行实验,实验方式如下:
两程序分别编译为norec和rec,使用time计算同一问题规模下程序的运行时间
time echo 20 ./rec >/dev/null
实验结果如下:(时间单位为s)
n
norec
rec
20
1.081
0.931
25
34.749
28.779
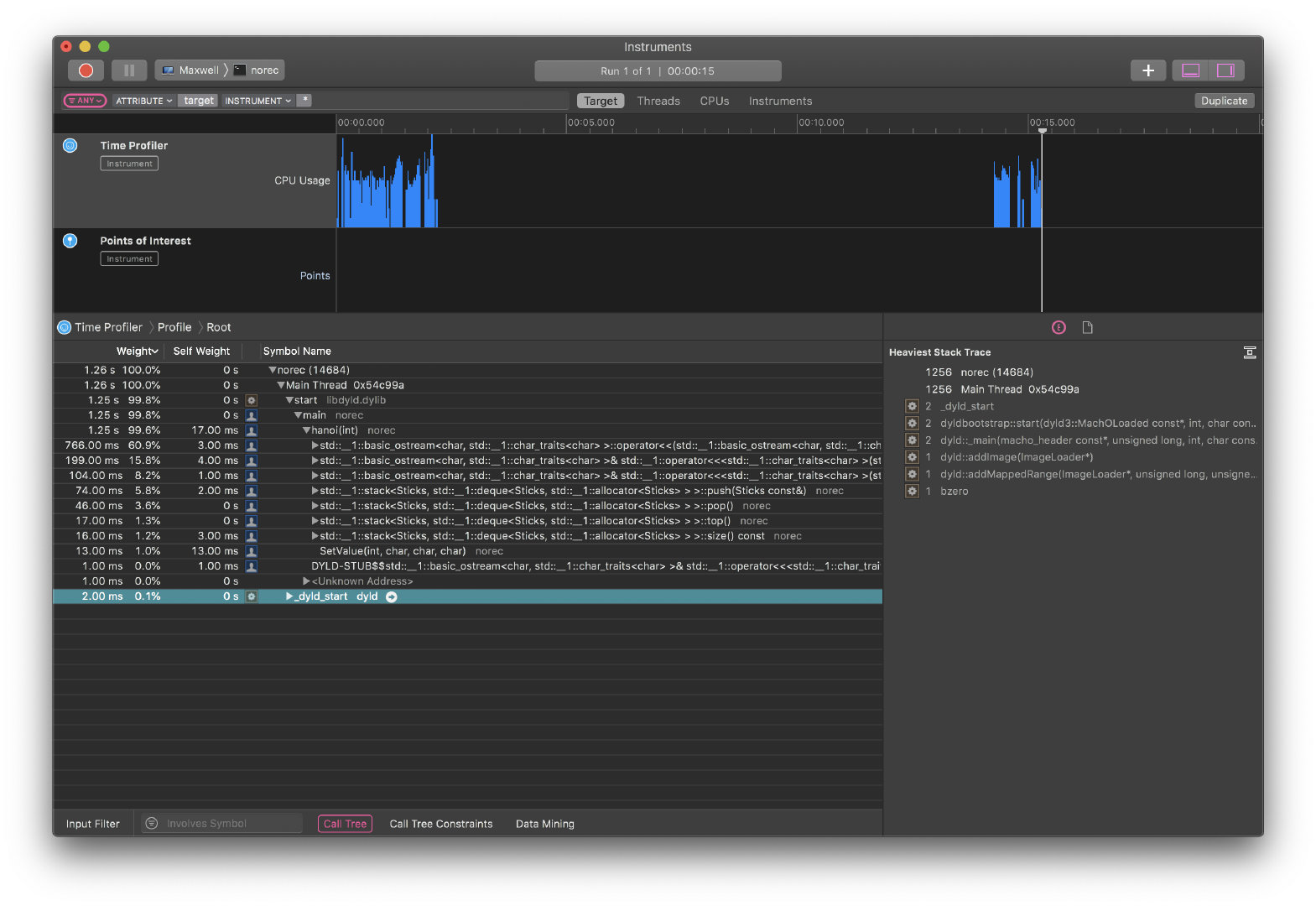
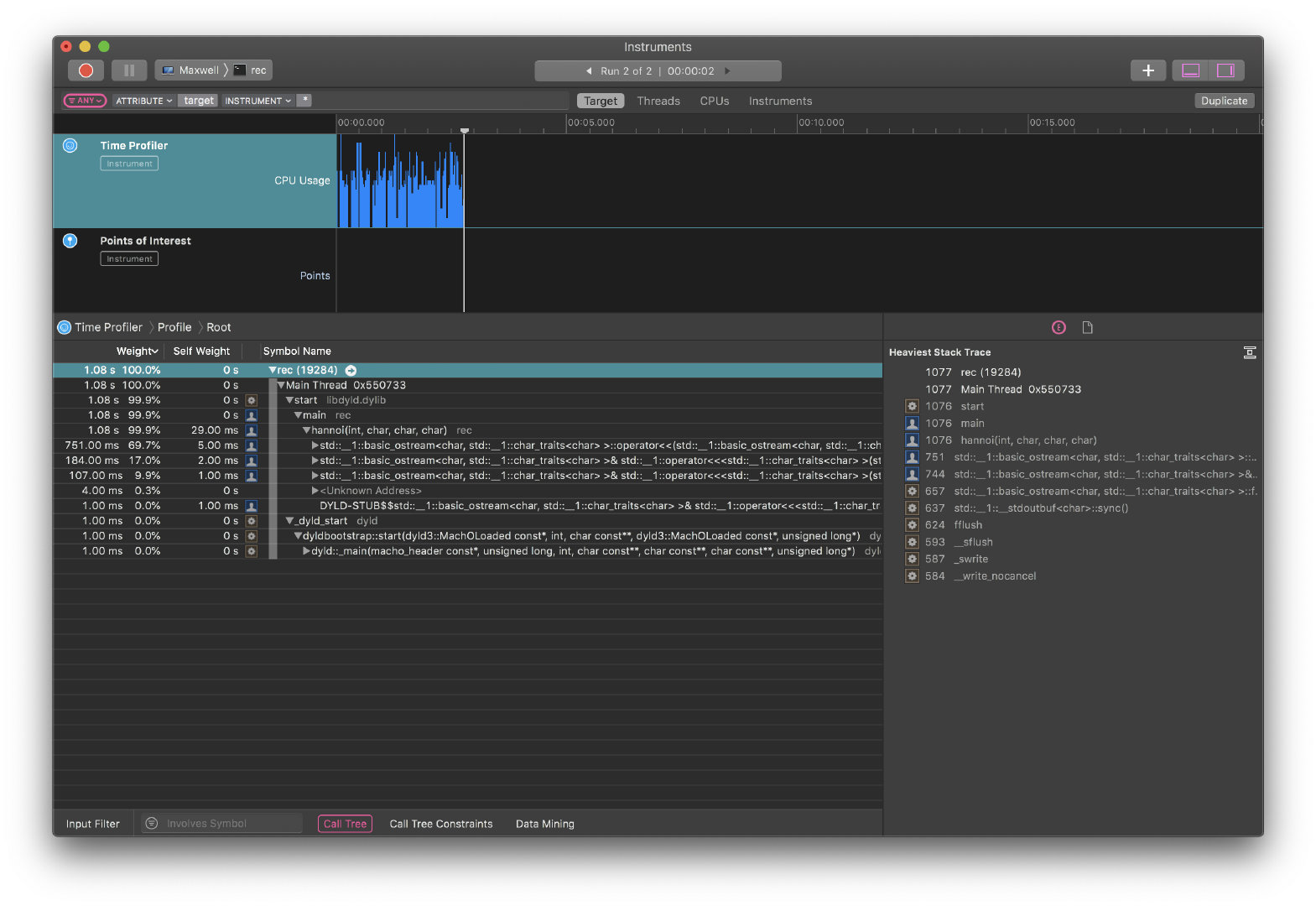
可以看到不使用递归的程序用时高于使用递归的程序。当问题规模增大时差距更加明显。 查找原因: 初步推测:rec中对栈操作的实现是CPU层面的支持,但norec中由程序模拟的栈操作要慢于汇编指令push,pop 确认原因: 问题规模为20时,对两个进程进行取样如下: norec进程:
rec进程:
对取样结果进行比较,确认推测是正确的。