《程序员的自我修养》- ELF文件分类
ELF文件即Execuable and Linkable File,可以分类为下面几种:
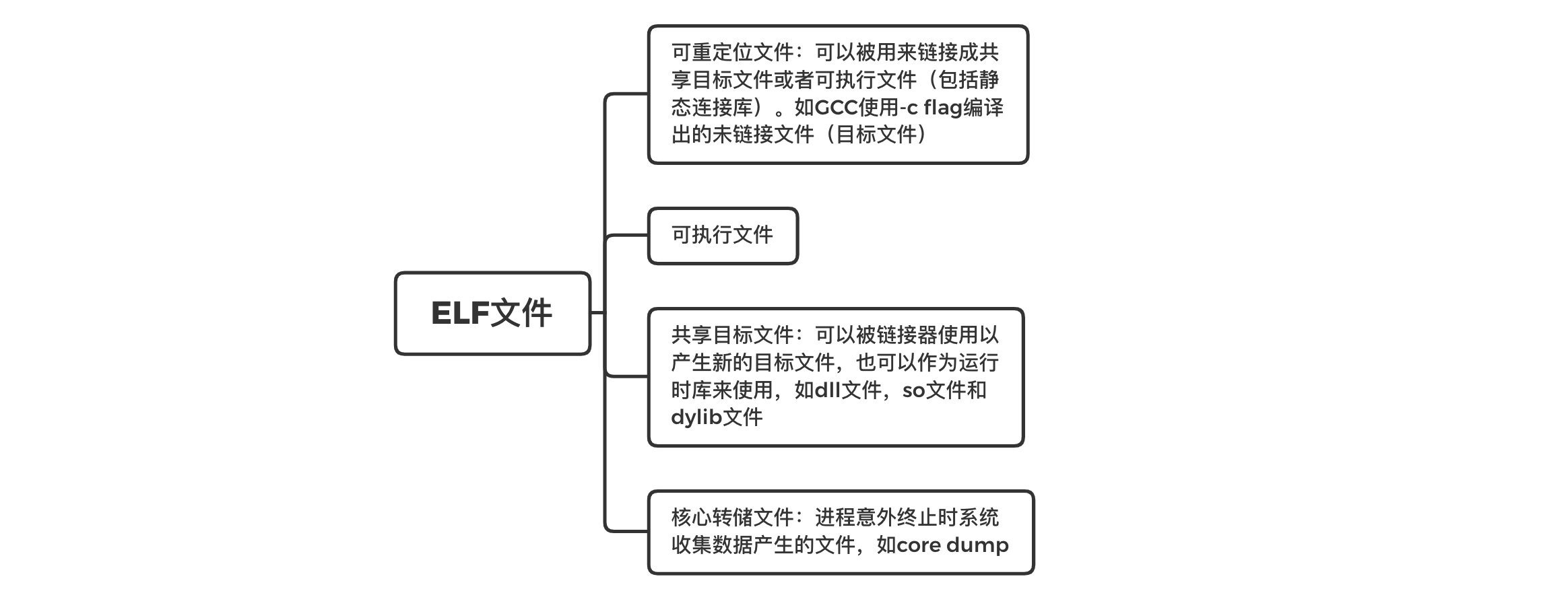
下面我们用例子来说明不太熟悉的共享目标文件和核心转储文件:
共享目标文件
使用共享目标文件的初衷在于减少程序占用的空间,如程序A和B都需要一个将浮点数进行平方倒数的功能,我们就可以这样写:
1 | |
然后使用命令gcc -shared -fPIC -o libsr.so C.c将其编译为动态链接库文件:
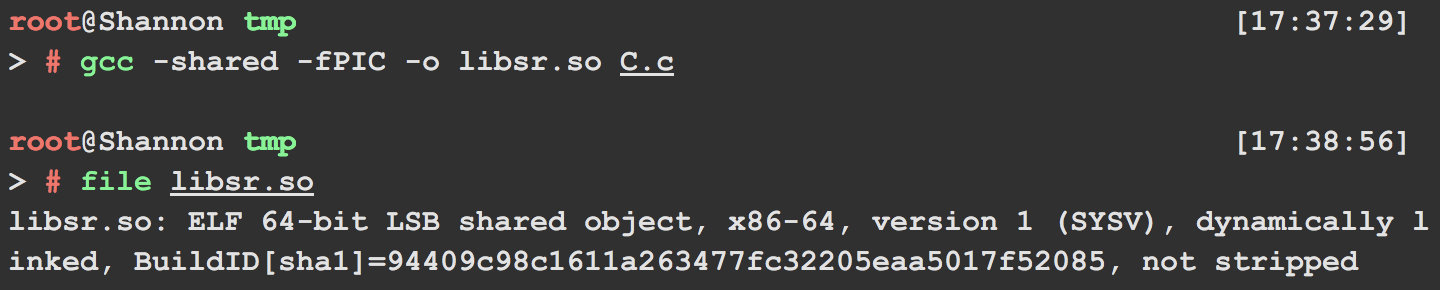
假设程序A如下:
1 | |
由于系统默认动态库路径存放在环境变量LD_LIBRARY_PATH中,因此可以执行export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$(pwd)暂时将当前目录添加到动态库路径。然后使用命令gcc A.c -lsr -L. -o A来在指明动态库的情况下将A.c编译为可执行文件A。运行A可以看到输出如下:

其实也可以使用头文件dlfcn.h来实现运行时加载某个共享库,将程序A改为下面形式:
1 | |
之后使用gcc A.c -ldl -A编译即可,flag
-ldl是为了告诉编译器程序使用了dlfcn头文件提供的共享库API,从而在编译时进行相应的一系列操作。这种写法可以在一定程度上实现共享库的“热插拔”,使得在不停止程序的情况下更新,添加或卸载共享库成为了可能。
核心转储文件
核心转储文件(core
dump)在调试程序或者做一些缺少信息的CTF题目时比较有用,它记录了程序发生指定的错误时的内存映像。可以使用ulimit -a命令查看当前core文件的最大大小。一般Linux系统该项为0,即不产生core文件。使用ulimit -c 100命令可以将core文件的大小限制在100k。下面我们尝试一下产生并分析一个core文件:
首先写一个会产生段错误的程序:
1 | |
该程序试图修改只读存储空间,因此产生了一个段错误和core文件。下面我们分析一下core文件: core文件的类型:

可以使用Python pwntools库来利用core文件得到需要的数据,示例如下:
