关于Cache存储器
零. 什么是Cache存储器
Cache存储器是多层次存储概念的更深扩展,它位于CPU和内存之间,是一块速度极快的存储缓冲区。
Cache与主存的不同之处在于两者的制造技术不同,主存采用的是动态随机存取存储器,即DRAM;而Cache采用的是静态随机存取存储器,即SRAM。DRAM存储数据的方式是利用电容器内的电荷数量的多寡来确定一个比特位,由于在现实中晶体管会有漏电电流的现象,导致电容上所存储的电荷数量并不足以正确的判别数据,而导致数据毁损。因此对于DRAM来说,周期性地充电是一个不可避免的条件。由于这种需要定时刷新的特性,因此被称为“动态”存储器。而与之不同的是,SRAM使用了一种更加复杂的机制,保证只要不掉电,写入后的数据就不会损毁,而且具有更强的抗干扰性能,其成本也更加高昂。
现代的计算机通常有多级的Cache,如L1,L2,L3等,如图:
一. Cache的作用
维基百科对于Cache在数据存取过程中作用的描述如下:
当CPU处理数据时,它会先到Cache中去寻找,如果数据因之前的操作已经读取而被暂存其中,就不需要再从随机存取存储器(Main memory)中读取数据——由于CPU的运行速度一般比主内存的读取速度快,主存储器周期(访问主存储器所需要的时间)为数个时钟周期。因此若要访问主内存的话,就必须等待数个CPU周期从而造成浪费。
之所以有缓存存在,是因为CPU对数据的访问呈现局部性的特征,即时间上的局部性和空间上的局部性。其中时间上的局部性是指CPU刚刚访问过的数据有更大的概率被再次访问,因此从内存中被访问过的数据会被存储在Cache中;空间上的局部性是指与被访问过的数据相邻的数据有更大的概率被访问,因此数据从主存拷贝到Cache中时是以行为单位的。
二. Cache的结构和运行细节
一般来讲,Cache分为几个组,每一个组中有若干行(即缓存块),而行也被划分成几个区域。
先看行的结构:

图片来源:维基百科。数字单位为bit
这个缓存块的大小是16B,它取自一个用直接映射的方式划分的Cache(即每一个组里面只有一行),可以看到这个缓存块对应着三个占一位的标识位,它们起到确保正确性,排解冲突,优化性能的作用。Tag用以配合索引值确定数据的位置,在Cache中,每一个组都被分配了一个索引值,在此例中就是每一行都有一个相应的索引值。
在这里我们需要注意的是,当程序发出读取某一地址内存的请求时,这个程序本身并不知道要读取的数据是否存在于Cache中,也就是说Cache对于程序来说是透明的。其实让Cache变得透明的正是这一系列的索引值和标签值,它们共同构成了虚拟地址,其中索引值一般是内存地址的低端部分,Cache中还维护着一个地址表,负责将内存地址定位到相应的缓存块上,上述结构如图所示:
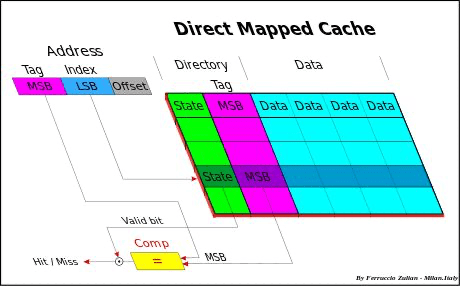
图片来源:知乎
图中Address下面的方块是内存块地址,注意内存映射到缓存上的方式是多对一映射,通过内存块地址计算索引的方式为模运算,即
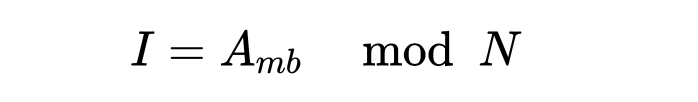
其中I为索引值,Amb为内存块地址,N为缓存块总数。注意一个内存块的大小就是Cache中一行中数据单元的大小,因为主存和Cache交换数据的单位就是行,因此假设缓存块大小是32Byte,那么也可以用如下公式从内存地址直接得到索引值。
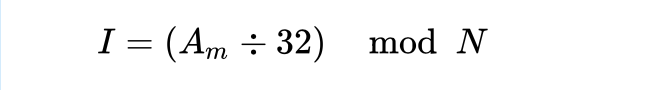
举一个例子:假设有一个数据总量为8KB(不包括tag,标志位),缓存块大小为32B,存储结构为直接映射的Cache存储器,那么这个缓存有256个缓存块。现假设内存大小为2048KB,内存地址范围从0x000000到0xFFFFFF,一个内存块的大小为32B,则内存块的地址范围是0x00000到0x7FFFF。那么地址为0x00AB3的内存块就被映射到索引为2739 mod 256 = 179的缓存块上,如果这个缓存块所对应的Tag与该地址的相应高位相吻合,那么就说明这一内存块中的数据存放在索引值为179的缓存块中。
如果程序发出了读取某一地址处内存数据的请求,而Cache中又刚好存放着对应内存块的数据,那么Cache就会直接返回数据到CPU,这一过程成为Hit,即命中。与之相对的就是Miss,即未命中。当未命中发生时,主存的该行数据会存入Cache中的相应行,为未来可能的读取做准备。
除了直接映射外,Cache的存储结构还包括N组相联甚至是全相联,即一个组中可能有多个行,每一组有对应的索引值,每一行有对应的Tag,读取数据时,Cache找到索引值,再通过Tag查找到相应行。如果查找Tag失败,就说明未命中。
直接映射虽然提高了查找速度,但是其明显的多对一的特性带来了需要频繁更换缓存块内容的问题。N组相联虽然缓解了多对一的问题,但是由于通过索引定位到相应组后,又需要通过标签值进行进一步的比对而降低了查找速度。因此实际问题中使用哪一种存储结构还需要因地制宜。
三. 启示
了解Cache的存在可以让我们妥当的组织程序,从而得到更快的运行速度,比如下面的数组遍历程序
1 | |
经过笔者的多次平行实验,两个函数运行时间的平均值分别为4926.5ms和5524.0ms,这几百毫秒的差距就来自于数组遍历的方式不同。数组在计算机内存中的存储方式如下图所示:

图中红框框住的部分就是数组a在内存中的样子,可以看到,数组的行中的数据在存入缓存时相对来说更容易处于同一个缓存块中,也就是说空间局部性更加明显 ,即更容易命中。也就是说在遍历数组时选取先遍历列再遍历行的方式更容易缓存命中,而先遍历行会导致缓存中出现大量冲突和无效数据。在后一种情况下缓存还不如不存在,因为程序运行反而多出了判断缓存是否命中的支出。